فناوریهای شناسایی بیومتریک به دلیل راحتی استفاده در جامعه مدرن، با پیشرفت اطلاعاتی و گسترش خدمات شبکهای، اهمیت بیشتری پیدا کردهاند. در این فناوریها، شناسایی چهره یکی از راحتترین و کاربردیترین فناوریها است، زیرا اجازه می دهد تا شناسایی از فاصله دور بدون نیاز به هیچ عملیات احراز هویت دستی صورت پذیرد. به طور کلی، شناسایی چهره به تغییرات ظاهر چهره به دلیل پیر شدن، نور محیطی و وضعیت پوزیشن حساس است. در این زمینه چالشهای فنی زیادی وجود دارد که باید حل شوند. با پیشرفت شگرفی که به واسطه روشهای یادگیری عمیق به دست آمده است، پیشرفتهای چشمگیری در شناسایی چهره به دست آمده است. در این مقاله ما به بررسی فناوری شناسایی چهره و معرفی برنامههای مرتبط با آن، از جمله تشخیص حمله با ارائه چهره، تخمین نگاه، شناسایی مجدد فرد و استخراج دادههای تصویری، میپردازیم. همچنین چالشهای پژوهشی که هنوز نیاز به حل دارند، مورد بحث قرار میگیرند.
بخش اول: مقدمه
با مقایسه با استفاده از کلمات عبور یا کلیدهای فیزیکی، فناوری شناسایی اثر انگشت و چشم، پتانسیل بالایی برای ورود به دنیایی جدید بدون نیاز به هیچ کسی برای تایید هویت یا احراز هویت دارد. به ویژه، فناوری شناسایی چهره با پیشرفت های اخیر در یادگیری عمیق ماشین و دقت شناسایی به سرعت در حال تحول است و به عنوان یک فناوری واعظ وعده ای که همزمان می تواند هم موثریت و هم راحتی را ارائه دهد، توجه پژوهشگران زیادی را به خود جلب کرده است. مزایای فناوری شناسایی چهره سه برابر است: (1) این فناوری امکان شناسایی از دور را فراهم می کند، (2) با استفاده از ابزار جهانی مانند گوشی هوشمند یا تبلت، بدون نیاز به دستگاه ویژه کار می کند و (3) با تکمیل تأیید توسط انسان در صورتی که بطور غیرمنتظره کار نکند، راحتی کاربران را تضمین می کند، در مقابل استفاده از شناسایی اثر انگشت. در همین زمان، فناوری شناسایی چهره با چالش های بحرانی مختلفی در پیاده سازی عملی مواجه است، از جمله تفاوت در تصاویر چهره یک شخص مشابه (چشم بسته یا چشمان خمیده، تغییر عبارت صورت، و...)، تغییرات در چهره با پیر شدن (از نوزاد تا پیرمرد)، شباهت های چهره (دوقلوها یا خواهران و برادران) و لوازم جانبی که یک بخشی از چهره را پوشش می دهند (عینک یا ماسک).
برای مقابله با چالش های یاد شده، NEC به عنوان پیشرو، از سال 1989 به فناوری شناسایی چهره بسیاری از پیشرفت ها را داشته است. ما در سال های 1996 و 2000، سیستم شناسایی چهره ۳D و ۲D را توسعه دادیم. در سال 2004، فناوری شناسایی چهره ما به سیستم مدیریت مهاجرت گمراه شد، که از آن پس در ۴۵ کشور به کار گرفته شده است.
از دیدگاه فنی، تکنولوژی شناسایی چهره ما با بهرهگیری از روشهای اصلی دوران خود در سه مرحله مختلف در حال تکامل بود: (1) مقایسه فاصله بین نقاط ویژگی (مانند ابروها و بینی) در سال ۱۹۹۰، (2) روشهای آماری مانند Eigenface و FisherFace در دهه ۲۰۰۰، و (3) روشهای اخیر مانند یادگیری عمیق ماشین پس از دهه ۲۰۱۰. در مرحله فعلی، تکنولوژی شناسایی چهره ما نیز به منظور بهینهسازی لوله پردازش خود به ویژگیهای ساخته شده دستی یا شبکههای عصبی کانولوشنی سبک (CNN) نیز روی میآورد، به دلیل محدودیت منابع محاسباتی در دستگاه.
علاوه بر این، NEC نیز به طور فعال در زمینه تحقیقات PAD (شناسایی حملات ارائه) فعالیت میکند، که هدف آن تمایز نمونههای چهره زنده از مصنوعات جعلی است، به منظور ایمن کردن احراز هویت بیومتریک. چگونگی توسعه یک PAD چهره محکم در تلفنهای هوشمند یکی از مهمترین مسائل عملی است. از دیدگاه اطمینان از امنیت احراز هویت بیومتریک، تکنولوژیهای کلیدی مختلفی قبلاً توسعه یافته است، از جمله احراز هویت مخفی که امکان مطابقت و شناسایی بدون رمزگشایی از ارزشهای ویژگی را فراهم میکند، و یک تکنیک بیومتریک قابل لغو که با استفاده همزمان از ویژگیهای بیولوژیکی و یک کلید مخفی ارزشهای ویژگی را تغییر میدهد.
ارجاع برینگر، Chabanne و Patey1–مرجع راتا، کانل و Bolle3].
ما بخشهای باقیمانده این مقاله را به شرح زیر تنظیم کردهایم. بخش دوم، با ارائه یک نمای کلی از تکنولوژی شناسایی چهره شامل شناسایی چهره، تطبیق چهره و چیدمان چهره مانند نمایش داده شده در شکل 1 و گزارش نتایج اخیر برای سنجش از طریق مقایسه با استانداردهای ملی و فناوری (NIST)، ارائه میشود. بخش سوم، پیشرفتهای اخیر در شناسایی حملات ارائه چهره را گزارش میدهد. بخش چهارم، برنامههای کلیدی شناسایی چهره شامل برآورد نگاه و شناسایی مجدد فرد را معرفی میکند. در ادامه، موارد استفاده در صحنههای واقعی در بخش پنجم معرفی میشوند. در نهایت، در بخش ششم، به نتیجهگیری از این مقاله و بحث درباره چالشهای آینده پرداخته میشود.

تصویر ۱. پردازش تشخیص چهره.
II. نمای کلی از تکنولوژی شناسایی چهره
A) شناسایی چهره
تکنولوژی شناسایی چهره دو وظیفه مهم دارد: تعیین مناطق چهره در تصویر در برابر پس زمینههای مختلف و تعیین چیدمان هر چهره، مانند موقعیت، اندازه و چرخش، به منظور بهبود عملکرد در برنامههای مرتبط با شناسایی چهره مانند سیستمهای شناسایی چهره. به دلیل استفاده معمول از این تکنولوژی در مرحله اول برنامهها (شکل 1)، در 20 سال گذشته الگوریتمهای شناسایی چهره مختلفی پیشنهاد شده است. یکی از رویکردهای موفق، بر اساس ساختار پیاپی شمارندههای AdaBoost معرفی شده در سال 2001 توسط Viola و Jones [مرجع Viola و Jones4] است. الگوریتم Viola-Jones برای اولین بار در تاریخ این تکنولوژی، در اصطلاحات دقت و سرعت عملکرد قابل توجهی را کسب کرد. این الگوریتم همچنین در برنامههای نرمافزاری متنباز مختلف پیادهسازی شده است، که منجر به استفاده گسترده از آن توسط بسیاری از پژوهشگران در زمینه بینایی ماشین شده است.
ما در سال 2005 یک طرح سلسله مراتبی نوآورانه که شامل شناسایی چهره و چشم استفاده کردیم [مرجع Sato، Imaoka و Hosoi5] با استفاده از GLVQ به عنوان یک طبقهبند برای بهبود عملکرد. در فرآیند شناسایی چهره، موقعیت چهره با استفاده از مؤلفههای پایین فرکانس با جستجو در تصاویر چند مقیاسی بهصورت درست تعیین میشود. شکل 2 جریان پیشنهادی سیستم شناسایی چهره را نشان میدهد. ابتدا، تصاویر چند مقیاسی از یک تصویر ورودی تولید میشوند، سپس نقشههای قابلیت اعتماد با استفاده از GLVQ تولید میشوند. در نهایت، این نقشهها از طریق تعامل بهدستآمده و نتایج نهایی بهدست میآیند. در فرآیند شناسایی چشم، موقعیت هر دو چشم با استفاده از مؤلفههای پایین تا بالا تصویر بهصورت دقیق تعیین میشود. با استفاده از این روش، ما همچنین به شناسایی چهره در زمان واقعی و چیدمان دقیق چهره دست یافتیم و سپس این روش را در بسیاری از برنامههای عملی به کار بردیم.
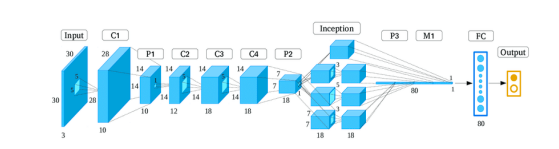
تصویر ۲. جریان پردازش تشخیص چهره پیشنهاد شده در سال ۲۰۰۵.
با توسعه برنامههای مرتبط با شناسایی چهره، در سالهای اخیر، تکنولوژی پیشرفته شناسایی چهره برای شناسایی چهره در شرایط دشوارتر مانند چرخش سر، تغییر نور و مانعهای مختلف مانند استفاده از ماسک جراحی، به طور معمول، ضروری شده است. رویکردهای سنتی مذکور برای پردازش چنین شرایطی به دلیل محدودیت ظرفیت نمایش ویژگیهای تصویر و طبقهبندیهایی که استفاده میکنند، قابل استفاده نیستند. به عنوان مثال، در زمینه شناسایی شیء با استفاده از یادگیری عمیق، دو رویکرد اصلی با نامهای Faster R-CNN و Single Shot MultiBox Detector پیشنهاد شدهاند. به طور کلی، شناسایی شیء بر اساس یادگیری عمیق (شامل روشهای فوق) از دو بخش تشکیل شده است: بخش اصلی که معادل استخراج ویژگی است و بخش شناسایی که موقعیت شیء و اطمینان از هر شیء را محاسبه میکند. در زمینه شناسایی شیء با استفاده از یادگیری عمیق، بسیاری از روشهایی که از پشتیبانی عمیق و بزرگ استفاده میکنند، پیشنهاد شده است و دقت بالایی را بهدست آوردهاند. در مواردی که الگوریتمها بر روی CPU و نه GPU در حال اجرا هستند، پشتیبانی از پشتیبانیهای سبک مانند MobileNet و ShuffleNet در سالهای اخیر پیشنهاد شدهاند و در حال حاضر در وظایف شناسایی شیء عمومی بهکار گرفته میشوند.
از آنجا که وظیفه شناسایی چهره در بسیاری از شرایط واقعی زندگی از جمله جستجوی چهره پرس و جو در برابر دهها میلیون چهره در پایگاه داده تصویر یا تحلیل چهرهها از هزاران دوربین IP که بر روی صدها سرور پردازش میشوند، استفاده شده است، الگوریتمی سریعتر برای بهدستآوردن مزیت تجاری رقابتی در این زمینه لازم است. بنابراین، ما با استفاده از یک پشتیبان ResNet و یک شبکه شناسایی یک بار، یک الگوریتم شناسایی چهره بهصورت زمانواقعی ایجاد کردهایم. در تکنولوژی خود، مدل خود را با تصاویر چهره و تصاویر بدن انسان از پایگاه داده داخلیمان آموزش دادیم تا موقعیت چهرهها و بدنهای انسان در تصاویر ورودی خروجی دهیم. همچنین، این تکنولوژی را به شناسایی مجدد فرد در بخش IV.B نیز اعمال کردیم. به دلیل تفاوتهایی در نحوه نشستن و لباسپوشی افراد، بدنهای انسان میتوانند تنوع ظاهری نزدیک به بینهایتی داشته باشند که آنها را از چهرهها پیچیدهتر میکند. برای مقابله با این پیچیدگی، تعداد زیادی تصویر از بدن انسان بهعنوان داده آموزشی در سیستم ورودی میشود که نشان دهنده تنوع بسیار زیاد افراد در حال انجام فعالیتهایی مانند راه رفتن و دویدن است. این امر امکان شناسایی چهرهها و بدنهای انسان در شرایط مختلف را فراهم میکند که در شکل ۳ نشان داده شده است. در الگوریتم خود، پارامترهای شبکه پشتیبان را با تمرکز بر پردازش CPU با دقت تنظیم کردیم. به عنوان نتیجه، شبکه پیشنهادی میتواند با توانایی ۲۵ فریم بر ثانیه بر روی یک هسته از Core i7 اجرا شود که در آن تصویر ۲K با ضریب کاهش ۲.۲۵ قبل از ورود به شبکه کاهش مییابد. شبکه چهرههایی با اندازه ۵۰ × ۵۰ پیکسل در تصویر اصلی ۲K شناسایی میکند که شرایط کاربردی را برآورده میکند. به عبارت دیگر، شبکه پیشنهادی قادر است تصویر ۲K را تقریباً بهصورت زمانواقعی و با دقت شناسایی بالا برای نهتنها چهرههای معمولی بلکه چهرههایی در محیط طبیعی پردازش کند.
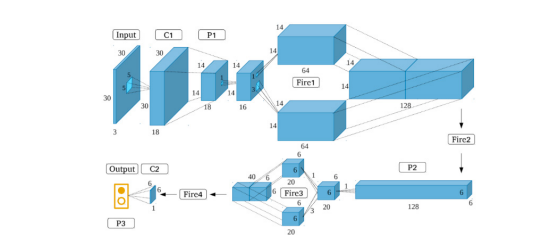
تصویر ۳. جریان پردازش تکنولوژی تشخیص چهره/بدن انسان بر اساس یک شبکه عصبی عمیق.
ب) ترازبندی چهره
شکل ۴ نمونهای از ترازبندی چهره را برای شناسایی نقاط ویژگی قسمتهای صورتی مانند چشم، بینی و دهان نشان میدهد. برای دستیابی به دقت بالا در شناسایی چهره، ترازبندی دقیق موقعیت و شکل قسمتهای صورتی بسیار مهم است زیرا دقت شناسایی چهره توسط حالت چهره و بیانیههای چهره تحت تاثیر قرار میگیرد. الگوریتم قوی ترازبندی چهره، به خصوص برای شناسایی چهره در شرایط طبیعی که محدودیتی در شرایط عکاسی وجود ندارد، ضروری است. از نظر کاربردی در محیطهای واقعی، هزینه محاسباتی پایین نیز یکی دیگر از نگرانیهای مهم است. الگوریتمهای جدید شناسایی چهره، به یک CNN بزرگ و زمانبر نیاز دارند. بنابراین، هدف ما کاهش هزینه محاسباتی ترازبندی چهره در مقایسه با شناسایی چهره است.

تصویر ۴. ترازبندی چهره برای تشخیص نقاط ویژگی اجزای چهره.
الگوریتمهای ترازبندی چهره اخیرا به دو گروه اصلی تقسیم میشوند: روشهای مبتنی بر ویژگی دستساز و روشهای مبتنی بر یادگیری عمیق.
درباره روشهای مبتنی بر ویژگی دستساز، در دهه ۲۰۱۰، مدلهای رگرسیون برشته معمولا استفاده میشدند. مدلهای رگرسیون برشته، چندین مرحله استخراج ویژگی دستساز و رگرسیون خطی دارند. ایجاد ویژگیهای دستساز موثر، مشکل اصلی مدلهای رگرسیون برشته برای ترازبندی سریع و دقیق چهره است. به عنوان مثال، اندازه توصیف کننده ویژگی، سرعت و دقت ترازبندی چهره را تحت تاثیر قرار میدهد. استراتژی گسترده تا دقیق، که در مراحل اول از توصیف کنندههای بزرگ و در مراحل بعدی از توصیف کنندههای کوچک استفاده میشود، باعث بهبود دقت میشود، اما همچنین سرعت را کاهش میدهد. با استفاده از هیستوگرام گرادیانها، استخراج سریع ویژگی یک توصیف کننده بزرگ با استفاده از تصاویر انتگرال هر گرادیان میسر شد [مرجع Takahashi and Mitsukura11]. در نتیجه، مدلهای رگرسیون برشته، بر روی پردازندههای معمولی، ترازبندی دقیق چهره را با بیش از ۱۰۰۰ فریم در ثانیه به دست آوردهاند.
از اوایل دهه ۲۰۱۰، روشهای مبتنی بر یادگیری عمیق به طور گسترده استفاده شدهاند. بر خلاف مدلهای رگرسیون برشته که ویژگیهای دستساز نیاز به طراحی دستی دارند، مدلهای یادگیری عمیق به طور خودکار نمایش ویژگی موثر را برای یک وظیفه ترازبندی چهره یاد میگیرند. با این حال، هزینه محاسباتی مدلهای یادگیری عمیق بسیار بیشتر از مدلهای رگرسیون برشته است. بنابراین، انتظار میرود از مدلهای یادگیری عمیق با هزینه محاسباتی کم برای کاهش هزینه استفاده شود. از سوی دیگر، مدلهای یادگیری عمیق برای بهبود دقت در شرایط سخت مانند پوششهای بزرگ و حالتهای سر، باتوجه به عملکرد نمایشی بالاتر از مدلهای رگرسیون برشته، موثر هستند.
دو گزینه برای الگوریتمهای ترازبندی چهره وجود دارد: مدلهای رگرسیون برشته سریع و مدلهای یادگیری عمیق قوی. در وابستگی به شرایط عملی، انتخاب یک الگوریتم مناسب برای ترازبندی چهره بسیار مهم است.
ج) تطبیق چهره
فناوری تطبیق چهره، یک بردار ویژگی از تصویر چهره استخراج میکند و تشخیص میدهد که آیا شخص موجود در تصویر شخصی است که قبلاً ثبت شده است یا خیر. تصویر پرسوجو و تصویر ثبتشده همیشه زیر شرایط یکسان گرفته نمیشوند. تغییرات در حالت، روشنایی، بیانیههای چهره و پیری، عوامل مهمی در کاهش عملکرد تطبیق چهره هستند.
برای حل مشکل تغییر حالت، ما از فناوری نرمال سازی چهره با استفاده از نقاط ویژگی چهره به دست آمده، استفاده کردهایم. فناوری نرمال سازی چهره، با استفاده از یک مدل شکل سه بعدی چهره متوسط جلو، حالت را به چهره جلویی و همچنین موقعیت و اندازه تصویر چهره اصلاح میکند. برای بیانیههای چهره و پیری که سخت است به آنها مدل سازی کنیم، از یک روش چند ویژگی تمیزدهنده استفاده میکنیم [مرجع Imaoka، Hayasaka، Morishita، Sato و Hiroaki12] تا ویژگیهای مفید برای شناسایی شخص از میزان بالایی از دادههای تصویر چهره استخراج کنیم و عملکرد را کاهش دهیم. با این روش، ویژگیهای مختلفی مانند جهت لبه و بافتهای محلی از تصویر چهره استخراج شده و بردارهای ویژگی به فضای ویژگی پروژه میشوند که تحت تاثیر تغییرات نباشد و برای شناسایی شخص موثر است. سپس، تصویر پرسوجو با تصاویر ثبتشده بر اساس زاویه بین بردارها در فضای ویژگی مقایسه میشود. با استفاده از دو روش مختلف، میتوانیم تطبیق چهره با دقت بالا و توانایی مقابله با عوامل تغییرات متنوع را داشته باشیم.
اخیراً با استفاده از فناوری مبتنی بر یادگیری عمیق، ما تطبیق چهره دقیقتری را دست یافتهایم. تصویر چهره نرمال شده ایجاد شده توسط روش نرمال سازی چهره ما، به یک CNN وارد میشود تا ویژگیهای بهینه (شکل ۵) را برای شناسایی دقیق فردی استخراج کند. برای این کار، از یک معماری مبتنی بر ResNet به همراه یک تابع خطای جدید و روش یادگیری متریک عمیق اصلی خود استفاده میکنیم [مرجع Sakurai، Hashimoto، Morishita، Hayasaka و Imaoka13، مرجع He، Zhang، Ren و Sun14]. این روش یادگیری متریک برای همزمان کاهش فاصله درون یک کلاس و بیشینه کردن فاصله بین کلاسها طراحی شده است. این باعث میشود سیستم کمتر به مشکلات شناسایی ناشی از انسداد جزئی، پیری، استفاده از ماسک و غیره حساس باشد. CNN آموزش داده شده با روشهای گفته شده، عملکرد شناسایی فردی قویتری را در برابر تغییرات در ظاهر نشان میدهد.
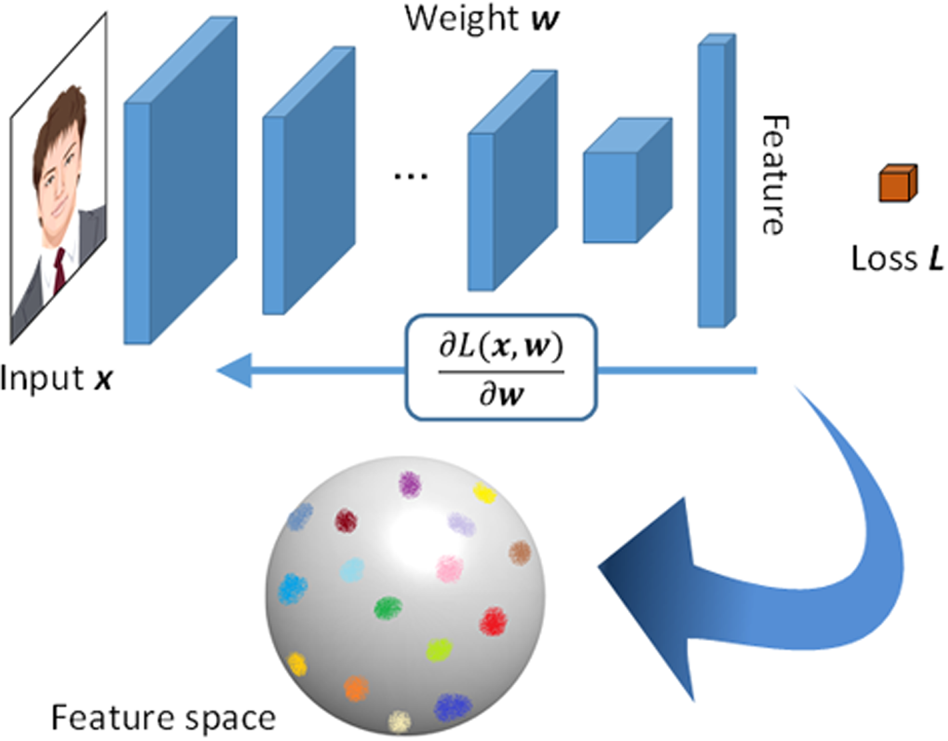
تصویر ۵. استخراج ویژگی با یک شبکه عصبی پیچشی برای تطبیق چهره.
د) نتایج بنچمارکینگ
در زمینه تطبیق چهره، به خصوص، تفاوتهای در دادههای ارزیابی معمولاً منجر به ارزیابی کاملاً متفاوت از دقت شناسایی میشوند. آزمون تولید کننده تطبیق چهره (FRVT) که توسط NIST اجرا میشود، با ارائه یک ارزیابی مقایسهای عادلانه و قابل اعتماد از الگوریتمهای تطبیق چهره، به بکارگیری عملی تکنولوژی تطبیق چهره کمک کردهاست. برای تضمین عدالت و قابلیت اعتماد آزمون، NIST پیشنیازهای ارزیابی را به یک شیوه بسیار دقیق تعریف میکند و از یک پایگاه داده مشترک استفاده میکند که برای بکارگیری عملی بسیار مناسب است. ما از زمانی که در چالش بزرگ چند بیومتریکی (MBGC) در سال ۲۰۰۹ [۱۵] شرکت کردیم، در اینگونه آزمونها شرکت کردهایم و در شاخصهای ارزیابی بسیاری در ارزیابی چند بیومتریکی (MBE) [مرجع Grother، Quinn و Phillips16]، FRVT2013 [مرجع Grother و Ngan17]، ارزیابی چهره در ویدیو (FIVE) [مرجع Grother، Ngan و Quinn18] ۲۰۱۵ و FRVT2018 [مرجع Grother، Grother، Ngan و Hanaoka19]، دقت شناسایی قابل توجهی داشتهایم. به ویژه، در FRVT2018، الگوریتم ما با نرخ اشتباه منفی ۰.۵٪ در نرخ اشتباه مثبت ۰.۳٪ در ثبت نام ۱۲ میلیون نفر بالاترین دقت را داشت. علاوه بر این، الگوریتم ما قابلیت تطبیق با تصاویر فردی که بیش از ۱۰ سال قبل گرفته شدهاند را نشان داد و در تطبیق چهره فوقالعاده سریع با زمان ۷ میلی ثانیه در ثبت نام ۱.۶ میلیون نفر، عملکرد بالا داشت.
III. پیشرفتهای اخیر در شناسایی حملات با تقلید تصویر چهره
اگرچه تأیید هویت با استفاده از چهره مزایای آشکاری نسبت به سیستمهای تأیید هویت سنتی دارد، اما یک ایراد اساسی مشترک با دیگر شیوههای تأیید هویت بیومتریکی دارد: احتمال نادرستی در رد و قبول. در حالی که رد نادرست کمتر مشکل ساز است، زیرا کاربر واقعی معمولاً میتواند تلاش دومی برای احراز هویت داشته باشد، قبول نادرست خطر امنیتی بالاتری را به همراه دارد. هنگامی که قبول نادرست رخ میدهد، سیستم ممکن است در حال حمله توسط یک مهاجم شرور با تلاش برای شکستن آن باشد. اکنون اساساً با استفاده از شبکههای اجتماعی، به دست آوردن تصاویر چهره آسانتر از همیشه است، که به حملات مختلف با استفاده از عکسهای چاپ شده یا فیلم ضبط شده، امکان پذیر میشود. بنابراین، تقاضای فناوریهای شناسایی حملات با تقلید تصویر چهره در تلاش برای تأمین امنیت سامانههای تطبیق چهره در حال افزایش است.
الف) پایگاههای داده حملات با تقلید تصویر چهره
حملات با تقلید تصویر چهره میتواند به دو دسته اصلی حملات ۲D و حملات ۳D تقسیم شود (شکل ۶). حملات ۲D شامل حملات چاپ و حملات بازیابی ویدیویی هستند، در حالی که حملات ۳D شامل حملات با ماسک تقلیدی ۳D میباشند. چندین پایگاه داده عمومی، این حملات را شبیه سازی میکنند. برخی از آنها شامل پایگاه داده NUAA [مرجع Tan، Li، Liu و Jiang20] و Print-Attack [مرجع Anjos و Marcel21] برای شبیه سازی حملات چاپی هستند. پایگاه داده Replay-Attack [مرجع Chingovska، Anjos و Marcel22]، CASIA Face Anti-Spoofing [مرجع Zhang، Yan، Liu، Lei، Yi و Li23]، MSU Mobile Face Spoofing [مرجع Wen، Han و Jain24] و Spoofing in the Wild (SiW، [مرجع Liu، Jourabloo و Liu25]) شامل حملات بازیابی به علاوه حملات عکس هستند. پایگاه داده حملات با ماسک ۳D [مرجع Erdogmus و Marcel26] و HKBU-Mask Attack با تنوع واقعی در جهان [مرجع Liu، Yang، Yuen و Zhao27] حملات با ماسک تقلیدی ۳D را شبیه سازی میکنند. راهکارهای نمونه برای هر نوع حمله در زیر خلاصه شدهاند.
تصویر ۶. نمونه ای از انواع حملات ارائه. (الف) حمله چاپ دو بعدی. (ب) حمله تکرار دو بعدی. (ج) حمله ماسک سه بعدی جعلی.
ب) راهکارهای مقابله با حملات ۲D
حملات ۲D، شامل حملات چاپی و بازیابی، ویژگی های برجسته مشترکی دارند: بافت سطحی و صفحهای. برای استفاده از بافت به عنوان ویژگی کلیدی، الگوریتمهای PAD که از الگوی دودویی محلی [مرجع de Freitas Pereira، Anjos، De Martino و Marcel28، مرجع Määttä، Hadid و Pietikäinen29] یا فیلتر گوسی [مرجع Kollreider، Fronthaler و Bigun30، مرجع Peixoto، Michelassi و Rocha31] استفاده میکنند، پیشنهاد شدهاند. برای شناسایی صفحهای بودن، دید سه بعدی [مرجع Singh، Joshi و Nandi32] و اندازه گیری عمق با عدم فوکوس [مرجع Kim، Yu، Kim، Ban و Lee33] برای شناسایی حملات تقلیدی استفاده میشوند.
تصویربرداری مادون قرمز میتواند برای مقابله با حملات بازیابی مورد استفاده قرار گیرد، زیرا نمایشگر تنها در طول موج نور قابل مشاهده (یعنی چهره در تصویر مادون قرمزی که از یک نمایشگر گرفته شده است، ظاهر نمیشود در حالی که در تصویر از یک فرد واقعی ظاهر میشود [مرجع Song و Liu34]). ویژگی سطحی دیگر حملات بازیابی الگوی مویر [مرجع Garcia و de Queiroz35] است.
ج) راهکارهای مقابله با حملات با ماسک ۳D
فناوریهای بازسازی و چاپ ۳D اخیراً کاربران بدنه را امکان تولید ماسکهای تقلیدی واقعگرایانه دادهاند [مرجع Liu، Yuen، Li و Zhao36]. یک راهکار نمونه برای مقابله با چنین حملات ۳D، تصویربرداری چندطیفی است. Steiner و همکاران [مرجع Steiner، Kolb و Jung37] اثربخشی تصویربرداری مادون قرمز موج کوتاه برای شناسایی ماسکها را گزارش کردهاند. رویکرد دیگر، فوتوپلتیسموگرافی از راه دور است که ضربان قلب را از تغییرات دورهای در رنگ چهره محاسبه میکند [مرجع Liu، Yuen، Zhang و Zhao38].
د) شبکههای عصبی عمیق انتها به انتها
ظهور یادگیری عمیق به محققان امکان ساخت یک طبقه بند انتها به انتها بدون نیاز به طراحی شاخص صریح را داده است. تحقیقات در مورد PAD چهره هم این استثناء نیست؛ یعنی، راهکارهای مقابله مبتنی بر شبکههای عصبی عمیق برای حملات عکس و همچنین حملات بازیابی و با ماسک ۳D پیدا شدهاند [مرجع Yang، Lei و Li39 - مرجع Nagpal و Dubey41].
ه) الگوریتم PAD مبتنی بر فلش برای دستگاههای همراه
سیستمهای شناسایی چهره در مکانهای مختلفی از فرودگاهها و ورودیهای دفاتر تا سیستمهای ورود به دستگاههای لبه استفاده میشوند. هر سایت دسترسی به سختافزار خود را دارد، مثلاً ممکن است به سروری دسترسی داشته باشد که محاسبات گران قیمت را انجام دهد و یا با دستگاههای تصویربرداری مادون قرمز مجهز شود. با این حال، ممکن است تنها به CPU با عملکرد پایین دسترسی داشته باشد. بنابراین، الگوریتم مناسب PAD چهره بسته به دسترسی به سختافزار متفاوت خواهد بود. ظهور فناوریهای یادگیری عمیق، پردازش تصویر با دقت بالا را با هزینه محاسباتی بالا ممکن کرده است که در رقابت با تواناییهای انسانی قرار دارد. از سوی دیگر، هنوز نیاز به الگوریتم PAD کارآمد با منابع محاسباتی حداقل است. به طور خاص، راهکارهای مقابله با حملات ۲D از جمله حملات عکس و نمایش، مهم است زیرا به دلیل هزینه تولید کمتر از حملات ۳D، احتمالاً بیشتر رخ خواهند داد. برای جلوگیری از حملات ۲D، به تازگی یک الگوریتم PAD چهره کارآمد که به حداقل سختافزار و فقط یک پایگاه داده کوچک نیاز دارد، پیشنهاد شده است که مناسب دستگاههای با منابع محدود مانند تلفن همراه است [مرجع Ebihara، Sakurai و Imaoka42].
با استفاده از یک دوربین نور قابل مشاهده، الگوریتم پیشنهادی ما دو عکس چهره، یک عکس با فلش و دیگری بدون فلش، را میگیرد. شاخص ویژگی پیشنهادی با بهرهگیری از دو نوع بازتاب تشکیل میشود: (۱) بازتابهای منعکس از منطقه قزحی که یک توزیع شدت خاص بسته به پایداری دارند و (۲) بازتابهای پخش شده از کل منطقه چهره که ساختار ۳D چهره فرد را نشان میدهد. سپس شاخص، با استفاده از ماشین بردار پشتیبانی (SVM، مرجع Vapnik و Lerner43 و مرجع Chang و Lin44)، در کلاس چهره زنده یا ساختگی طبقهبندی میشود.
آزمایشهای ما درباره الگوریتم پیشنهادی در سه پایگاه داده عمومی و یک پایگاه داده داخلی نشان داد که دقت آن به طور قابل توجهی بهتر از طبقهبندی شبکه عصبی عمیق end-to-end است (شکل ۷ (a)، جدول ۱). علاوه بر این، سرعت اجرای الگوریتم پیشنهادی تقریباً شش برابر سرعت شبکههای عصبی عمیق بود (شکل ۷ (b)). معیارهای ارزیابی برای این آزمایشها شامل نرخ خطا در طبقهبندی حمله، نرخ خطا در طبقهبندی ارائه بونافید (BPCER) و نرخ خطا در طبقهبندی متوسط (ACER) بود که به دنبال ISO / IEC 30107-3 بود. لازم به ذکر است که یکی از مشکلات در ارزیابی این است که الگوریتم پیشنهادی ما نیاز به جفت عکس با و بدون فلش دارد. با این حال، ما نمیتوانیم به اشخاص زنده حاضر در پایگاههای داده عمومی دسترسی داشته باشیم. بنابراین، به منظور به دست آوردن معیارهای معادل BPCER و ACER، یک بخش از چهرههای زنده یک پایگاه داده داخلی را از مجموعه دادههای آموزش جدا کرده و آنها را به عنوان جایگزین چهرههای زنده پایگاههای داده عمومی استفاده کردیم. در ادامه به این معیارهای شبیهسازی شده به عنوان sBPCER (نرخ خطا در طبقهبندی ارائه بونافید شبیهسازی شده) و sACER (نرخ خطا در طبقهبندی متوسط شبیهسازی شده) ارجاع میدهیم (شکل ۸).
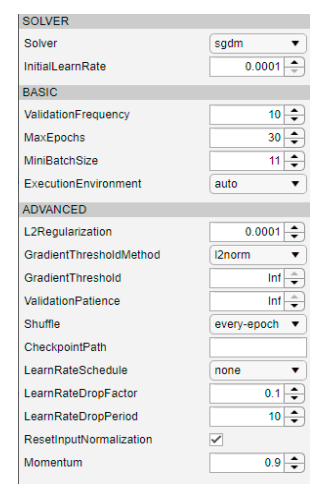
تصویر ۷. نتایج آزمایش سرعت و دقت، تطبیق داده شده از مرجع [مرجع ابیهارا، ساکورای و ایمائوکا ۴۲]. (الف) دوطرفه ANOVA برای مقایسه SpecDiff و ResNet4. BPCER و ACER نشان دهنده استفاده از sBPCER و sACER برای ارزیابی پایگاه داده های عمومی هستند، در حالی که BPCER و ACER اصلی برای ارزیابی پایگاه داده داخلی استفاده می شود. مقادیر p حاصل شده نشان دهنده معناداری آماری در APCER و (s)ACER هستند. (ب) خلاصه سرعت اجرا. توصیفگر ProposeSpecDiff با هسته SVM RBF با ResNet4 مقایسه شده است. سرعت اجرا بر روی iPhone7، iPhone XR و iPad Pro اندازه گیری شده است.
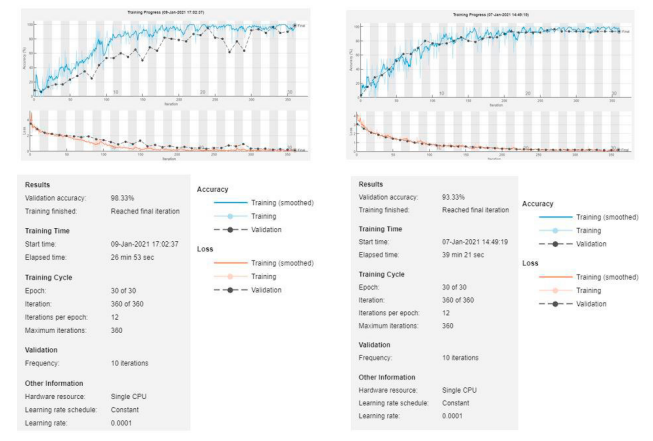
جدول ۱. خطاهای اعتبارسنجی میانگین الگوریتمهای انتخاب شده.
برای جزئیات آزمایشی، به [مرجع ابیهارا، ساکورای و ایمائوکا ۴۲] مراجعه کنید.
معناداری ضخیم (ANOVA) به دنبال آن توست کرامر چند مقایسه ای برای نشان دادن اینکه روش پیشنهادی ما دقتی قابل توجه و معنادار آماری را نسبت به ResNet4 داشت، آورده شده است.
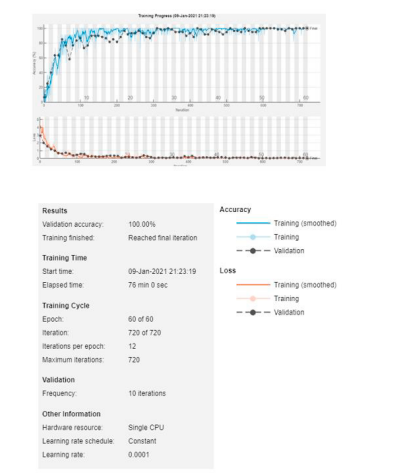
تصویر ۸. منحنی های میانگین خطای تجاری (DET) در طول ۱۰ آزمایشات متقابل ۱۰ برابر، تطبیق داده شده از مرجع [مرجع ابیهارا، سارای و ایمائوکا ۴۲]. Implicit3D الگوریتم دیگری بر اساس فلش [مرجع دی مارتینو، کیو، ناگنالی و ساپیرو ۴۶] برای مقایسه گرفته شده است. (۱) پایگاه داده NUAA. (۲) پایگاه داده Replay-Attack. (۳) پایگاه داده SiW.کو
سیستمهای PAD در حال حاضر بخشی اساسی از سیستمهای احراز هویت چهره برای استقرار امنیتی هستند. برای اطمینان از دقت بالاتر، دو رویکرد زیر را به عنوان موثر در تقویت سیستمهای PAD در نظر میگیریم. اول، ترکیب چندین الگوریتم PAD. هر الگوریتم PAD دارای محدودیتهای خود است، بنابراین تکیه بر یک الگوریتم تنها به خطر امنیتی افزوده میشود. دوم، استفاده از چندین مدالیتی به صورت همزمان. بیشتر حملات ساختگی این روزها شکل مشابهی با چهرههای زنده در دامنه نور قابل مشاهده دارند، بنابراین استفاده تنها از یک الگوریتم مبتنی بر نور قابل مشاهده ممکن است خطر را افزایش دهد. به عنوان مثال، الگوریتم PAD مبتنی بر فلشی که در بالا ذکر شد، نمیتواند حملات ماسک ۳D را تشخیص دهد. ترکیب الگوریتم مبتنی بر فلش با یک الگوریتم PAD مبتنی بر مادون قرمز، مقاومت در برابر حملات ساختگی مختلف را به همراه شرایط محیطی مختلف (مانند نور نامطلوب) تضمین میکند.
IV. کاربردهای شناسایی چهره
در این بخش، پیشرفتهای اخیر کاربردهای کلیدی با بهرهگیری از فناوری شناسایی چهره را با مزایای آن اعمال میکنیم، از جمله برآورد نگاه و شناسایی مجدد فرد.
A) برآورد نگاه
برآورد نگاه یکی از کاربردهای شگفتانگیزی است که میتواند با کمک چشمان کاربران علاقهها یا نیات آنها را ثبت کند. ما یک فناوری برآورد نگاه از راه دور (شکل ۹) توسعه دادیم که تشخیص در زمان واقعی جهت نگاه فرد را از راه دور و حتی در هنگام استفاده از دوربینهای موجود، فراهم میکند.

تصویر ۹. خلاصه فناوری تخمین نگاه از راه دور.
فناوریهای سنتی با استفاده از دستگاههای ویژه دارای چراغهای مادون قرمز و دوربینهای پیشرفته هستند که نوری که از چشم فرد منعکس میشود را تشخیص میدهند تا جهت نگاه فرد را تخمین بزنند. در مقابل، فناوری ما از تطبیق چهره، یکی از اجزای کلیدی شناسایی چهره ما، برای شناسایی ویژگیهای مربوط به چشم (مانند مردمک و گوشههای چشم) در تصاویر گرفته شده توسط دوربینهای معمولی (شامل دوربینهای وب، نظارت، تبلت و گوشیهای هوشمند) استفاده میکند، بدون نیاز به تجهیزات ویژه. پس از تطبیق چهره، ویژگیهای تصویر توسط یک شبکه عصبی مبتنی بر ResNet استخراج میشوند و سپس جهت نگاه فرد بر اساس ویژگیهای استخراج شده تخمین زده میشود.
از آنجایی که تاکنون یک روش برآورد نگاه بر اساس شبکه عصبی عمیق [47] پیشنهاد شده است، ما به دنبال یک شبکه سبک برای پردازش در زمان واقعی هستیم. ما یک فرمولبندی جدید از دانش فشردهسازی برای مسائل رگرسیون [48] پیشنهاد دادیم. در این فرمولبندی، ما دو بخشی داشتیم: (1) یک تلفات جدید برای لغو خارج از حالت عادی استاد که با استفاده از پیشبینی مدل استاد، خارج از حالت عادی در نمونههای آموزش را رد میکند، و (2) یک شبکه چند وظیفهای. شبکه چند وظیفهای هم آموزش برچسبهای آموزش با نویز و هم خروجی مدل استاد را تخمین میزند، که انتظار میرود برچسبهای نویزی را با اثرات حفظ تغییر دهد. آزمایشات ما در [48] نشان داد که خطای میانگین مطلق (MAE) روش پیشنهادی با دانش فشردهسازی ما در MPIIGaze [47] برابر با 1.6 در درجه است. همچنین، ویژگی انحراف معیار آن 0.2 بود. این نشان میدهد که روش پیشنهادی، با خطای 2.5 درجه یا کمتر در اکثر موارد، تشخیص جهت نگاه فرد را با دقت بالا ممکن میکند. در عین حال، MAE روش آنها [47] برای پروتکل ارزیابی leave-one-person-out به ترتیب 5.4 در درجه و برای پروتکل ارزیابی شخصمحور، 2.5 در درجه بود. ما نمیتوانیم مقایسه منصفانهای با کار قبلی ارائه دهیم زیرا پروتکل ارزیابی آنها را دنبال نکردیم، اما در [48] پایگاه داده MPIIGaze را به صورت تصادفی به مجموعه آموزش و آزمایش تقسیم کردهایم. با این حال، ارزیابی تصادفی ما در میان پروتکلهای ارزیابی استفاده شده در [47] وجود دارد و نشان میدهد که روش پیشنهادی ما دقت بهتری نسبت به کار قبلی داشته است. همچنین، در این مقاله نمیتوانیم مقایسهای بین فناوری ما بر اساس تصاویر RGB و فناوریهای سنتی با استفاده از تصاویر IR ارائه دهیم زیرا پایگاه داده عمومی با تصاویر RGB و IR زیر شرایط یکسان وجود ندارد.
علاوه بر این، در فناوری برآورد نگاه از راه دور ما، با اتخاذ روش تطبیق چهره ما که در بخش II.B توضیح داده شده است، پاسخ به تصاویر با کیفیت پایین و تغییرات در روشنایی تقویت شده است تا بتوان جهت نگاه فرد را حتی زمانی که از دوربین تا 10 متر دور هستند شناسایی کرد، همانطور که در شکل 9 نشان داده شده است، زیرا روش تطبیق چهره ما حتی در چنین حالتی بسیار قوی است. این تقویت باعث میشود که فناوری برآورد نگاه ما مناسب برای کاربردهای واقعی مانند تشخیص خودکار محصولاتی که توجه خریداران را به خود جلب میکنند در فروشگاههای خردهفروشی باشد. با استفاده از قدرت این فناوری، میتوانیم جهت نگاه عابران پیاده را تحلیل کرده و به بهینه کردن قرار دادن اعلانهای مهم در خیابانهای عمومی کمک کنیم. این فناوری همچنین میتواند با نظارت بر رفتار چشم افراد مشکوک، به ایمنی و امنیت جوامع ما کمک کند
B) شناسایی مجدد فرد
بدین ترتیب، شناسایی مجدد فرد باید به عنوان یکی دیگر از کاربردهای کلیدی تشخیص چهره شمرده شود که افراد را از تصاویری که توسط دوربینهای غیر همپوشانی گرفته شدهاند، شناسایی (یا بازیابی) میکند. مانند پردازش مطابقت چهره، شناسایی مجدد فرد برای تعیین اینکه یک فرد در گالری همان فرد است یا نه، استفاده میشود. تفاوت این است که شناسایی مجدد فرد از تصاویر کل بدن به عنوان پایه شناسایی استفاده میکند، به جای استفاده فقط از تصاویر چهره. در این حالت، تصویر کل بدن فرد به یک استخراج کننده ویژگی ورودی داده میشود، بردارهای ویژگی استخراج شده در تصاویر گالری با بردارهای فرد مقایسه میشوند و در نهایت امتیازهای شباهت محاسبه میشوند. امتیاز شباهت سپس برای تعیین اینکه موضوع در گالری شخص استفاده میشود یا خیر.
یکی از روشهای معمول برای شناسایی مجدد فرد، طراحی ویژگیهای قوی است. به عنوان مثال، Liao و همکاران [49] ویژگیهای Local Maximal Occurrence (LOMO) را توسعه دادند که بیشینه بین باکسهای هیستوگرام محلی را برای مدیریت تغییرات دیدگاه استفاده میکنند. یکی دیگر از تکنیکهای حل وظیفه شناسایی مجدد فرد، یادگیری یک معیار تمایزی است [49، 53-56]. به عنوان مثال، Li و همکاران [54] تابع تصمیم تطبیقی محلی (LADF) را ارائه دادند که در آن یک معیار را یادگیری میکنند و یک قانون برای آستانهگذاری نیز یادگیری میکنند. اخیراً، شبکههای عصبی مصنوعی در بسیاری از وظایف بینایی رایانه عملکرد عالی از خود نشان دادهاند. در وظیفه شناسایی مجدد فرد، شبکههای عصبی نیز به خوبی عمل کردهاند [57-59]. Xiao و همکاران در [59] با استفاده از تصاویر از چندین مجموعه داده (دامنه)، ویژگیهای عمیق بهتری را یاد میگیرند و از یک Dropout جدید برای تنظیم مجدد CNN به یک مجموعه داده خاص استفاده میکنند.
مانند بیشتر وظایف شناسایی، دقت شناسایی مجدد فرد تحت تأثیر پس زمینه، دیدگاه، القاء، تغییر مقیاس و اندازهگیری قرار دارد. معمولاً، ما بر روی مشکل تغییرات پس زمینه تمرکز میکنیم. وظیفه شناسایی مجدد فرد شامل استخراج ویژگیها از تصاویر افراد و استفاده از معیار تمایزی برای مطابقت ویژگیها است. فرآیند استخراج ویژگی باید به اندازه کافی قوی باشد تا با تغییرات پس زمینه برخورد کند. همانطور که در شکل 10 نشان داده شده است، پسزمینه در جفت تصاویر بسیار شبیه به هم است. این موضوع معمولاً منجر به نتایج مطابقت غلط در تصاویر غیر همراه میشود.

تصویر ۱۰. نمونه های زوج تصاویر غیر همسان با پس زمینه های مشابه. تصاویر از مجموعه داده VIPeR [مرجع گری، برنان و تائو ۶۰] انتخاب شده اند.
ما با استفاده از نقشههای جذابیت در یک طرح dropout قطعی برای کمک به یک شبکه عصبی پیچشی در یادگیری ویژگیهای قوی، به این مشکل پرداختیم. ما یک نقشه جذابیت را به عنوان احتمال یک پیکسل تعریف کردیم که به پیش زمینه (فرد) یا پس زمینه تعلق دارد. مانند محاسبه نقشههای جذابیت کلاس توسط Simonyan و همکاران [61] با بازگشت پشتیبانی از CNN چند کلاس، ما نقشههای جذابیت خروجی دودویی را با CNN محاسبه کردیم. با توجه به برچسب y تصویر ورودی x و یک طبقه بند دودویی f(x)، ما میخواهیم یک تصویر x0 را پیدا کنیم، به طوری که امتیاز f(x0) بیشینه شود. با توجه به [61]، ما میتوانیم طبقه بند f(⋅) را با تقریب تایلور خود به عنوان رابطه (1) تخمین بزنیم.
(1)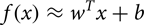
جایی که b یک عبارت بایاس و وزنهای w توسط رابطه (2) زیر داده شده است.
(2)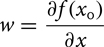
از رابطه (1)، مشخص است که مشارکت پیکسلها در x توسط w داده میشود. با استفاده از یک ConvNet برای مسئله طبقهبندی دودویی (انسان یا نه)، ما میتوانیم به ورودی بازگردیم و w را با توجه به رابطه (2) بدست آوریم.
این نقشهها بخشهای تصویر را که به امتیاز یا برچسب آن تصویر کمک میکند، برجسته میکند و باید برای شامل بخشهای دیگر فرد نیز صاف شود. ما نقشه جذابیت را با یک CNN با استفاده از یک تکنیک dropout قطعی ترکیب کردیم تا عملکرد را بهبود بخشیم. جریان کار تکنیک، که در شکل 11 نشان داده شده است، به دو مرحله تقسیم میشود. در مرحله اول، برای هر تصویر رنگی ورودی، یک نقشه جذابیت محاسبه میشود. این نقشه دارای اندازه یکسان با تصویر ورودی است با این تفاوت که فقط یک کانال دارد. برای روشن شدن، نقشه جذابیت در شکل 11 با اضافه کردن رنگهای مصنوعی نشان داده شده است. در مرحله دوم، تصویر رنگی و نقشه جذابیت آن به یک CNN ورودی داده شده و این CNN از dropout قطعی استفاده میکند و شناسه تصویر ورودی را خروجی میدهد.
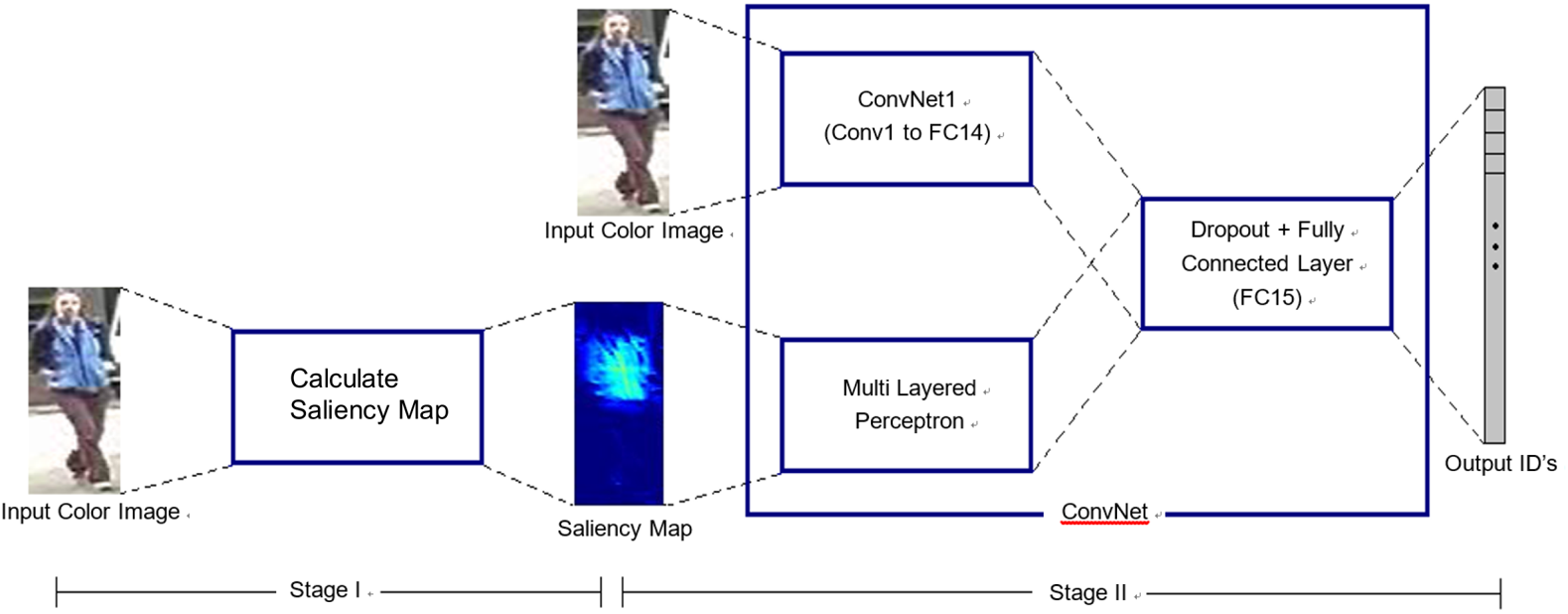
تصویر ۱۱. گردش کار تکنیک Dropout. در مرحله اول، تصویر رنگی ورودی است و نقشه برجستگی محاسبه میشود. این نقشه در مرحله بعدی همراه با تصویر اصلی برای یادگیری ویژگی های قوی توسط یک شبکه عصبی پیچشی (CNN) استفاده میشود. خروجی به صورت برداری از شناسه ها نشان داده شده است، اما کدهای CNN یادگرفته شده در لایه قبل از آخر نیز میتواند به عنوان ویژگیهای استخراج شده استفاده شود.
برای ارزیابی کارایی تکنیک ما، آزمایشها را بر روی یک مجموعه داده عمومی انجام دادیم و مشارکت اجزای مختلف را اندازه گیری کردیم. عمدتاً عملکرد سه سیستم را مقایسه کردیم:
(1) CNN1 با تصویر رنگی به عنوان ورودی و بدون dropout قطعی،
(2) CNN1 با تصویر چهار کاناله به عنوان ورودی، یعنی RGB با نقشه جذابیت و بدون dropout قطعی، و
(3) CNN کامل با تصاویر رنگی به عنوان ورودی برای CNN1، نقشه جذابیت به عنوان ورودی برای Multi Layered Perceptron و استفاده از dropout قطعی.
ما دقت Cumulative Matching Characteristic (CMC) را به عنوان معیار ارزیابی استفاده کردیم. نتایج عملکرد در جدول 2 خلاصه شدهاند، جایی که سه ردیف اول اجزای مختلف روش ما را فهرست میکند. میتوانیم ببینیم که عملکرد CNN1 (ردیف 1) بهبود یافت وقتی تصویر چهار کاناله به جای تصویر رنگی سه کاناله ورودی شد (ردیف 2). این نشان میدهد که اطلاعات جذابیت برای وظیفه بازشناسی مفید است. علاوه بر این، با استفاده از این اطلاعات به شیوه اصولی با روش ما، میتوان بهبود عملکرد اضافی ایجاد کرد (ردیف 3). این نشان میدهد که با استفاده از اطلاعات جذابیت، میتوانیم ویژگیهایی که یک CNN یاد میگیرد، را به صورت قویتر و مقاومتر بهبود بخشیم.
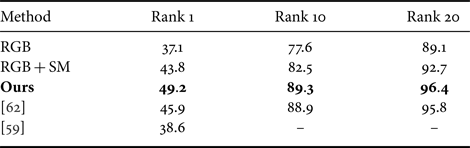
جدول ۲. دقتهای CMC در VIPeR.
"RGB" به معنای ورودی تنها تصویر رنگی است و "RGB + SM" به معنای ورودی یک تصویر با چهار کانال است. "ما" به معنای تصویر رنگی و نقشه برجستگی مربوط به آن ورودی است و Dropout قطعی استفاده شده است.
دقت معناداری که در روش پیشنهادی ما شامل تمامی عملکردهای ما است، برجسته شده است.
با تشکر از مزایای مذکور در فناوری شناسایی چهره ما، ما قادریم تا از این فناوری برای برنامههای بازیابی و استخراج در ویدیوهای نظارتی بزرگ مستقیماً استفاده کنیم، به جای استفاده از تکنیکهای سنتی پیگیری شخص. برای نشان دادن عملکرد چنین رویکردی، در این بخش، سه برنامه صنعتی واقعی را معرفی میکنیم.
اولاً، یکی از مشکلات شناخته شده در پیگیری شخص در چندین دوربین، ناتوانی در نظارت بر مناطق بزرگ بدون همپوشانی دوربین است. چون تکنیکهای پیگیری سنتی نیازمند فریمهای پیوسته ای هستند که شخص مورد نظر در آنها ظاهر شود، در صورتی که دو فریم از دو دوربین مختلف با هیچ همپوشانی دید دوربین باشد یا تصاویر از زوایای مختلفی گرفته شود، بازیابی پیگیری همان شخص بسیار دشوار خواهد بود.
برای رفع این مشکل، ما به طور کامل از تکنیکهای پیگیری سنتی صرف نظر کرده و به جای آن، صرفاً با استفاده از شناسایی چهره، بازیابی شخص را در چندین دوربین انجام میدهیم تا به پیگیری شخص برسیم. ایده کلیدی به این صورت است که ابتدا ما به طور ساده، جفتشدن بین هر دو ویژگی چهره استخراج شده از ویدیوهای چند دوربینی را انجام میدهیم. سپس، شخص یکسانی که از فریمهای مختلف و غیر پیوسته استخراج شده است، به راحتی به یک دنباله پیگیری متصل میشود که تأثیر یک پیگیری شخص دارد. با این حال، محاسبات جفتشدن چهره با پیچیدگی O(N2)، که در آن N تعداد ویژگیهای چهره است، بسیار پرهزینه است. در صورتی که فرض کنیم تنها 10K ویژگی چهره داریم، با این حال باید 100 میلیون بار جفتشدن چهره انجام دهیم. آشکار است که چنین محاسباتی، بدون توجه به سرعت پیگیری چهرهای که ما داریم، بسیار ناکارامد است.
برای حل این مشکل، ما یک روش نوین ایندکسینگ به نام Luigi [1] طراحی کردیم تا دادههای ویژگی را به صورت دینامیک به یک ساختار درختی سلسله مراتبی بر اساس امتیازهای شباهت بین هر دو ویژگی چهره، سازماندهی کنیم. ما به صورت کلی به ساختار درخت Luigi میپردازیم و گروههای چهره مشابه را در امتداد مسیر بازدید در سطح برگ نزدیک تشکیل میدهیم، همانطور که در شکل 12 نشان داده شده است. با این رویکرد نوین، پیچیدگی محاسباتی اولیه O(N2) به حداکثر O(NlogN) در شرایط ایدهآل کاهش مییابد، که باعث میشود بازیابی شخص بدون پیگیری سنتی به صورت عملی و کارآمد انجام شود.
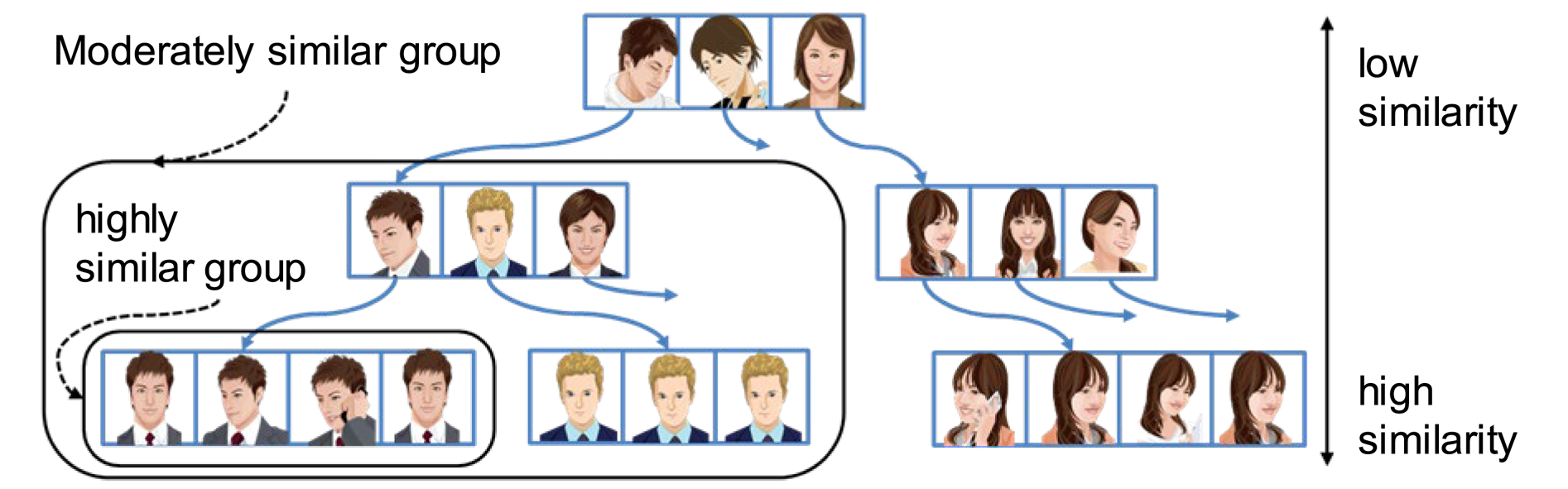
تصویر ۱۲. نمونهای از گروه بندی چهره با فهرست لوئیجی. [منبع مقاله/مرجع]
ما در توسعه سیستم خودکار (AntiLoiter و تجسمی آن VisLoiter) برای کشف افراد بیهدف از ویدیوهای نظارتی طولانی مدت، از ایندکس Luigi استفاده کردیم. یک تصویر از سیستم VisLoiter در شکل 13 نشان داده شده است که نتایج کشف بصری افراد بیهدف که بیشتر در چندین دوربین دیده شدهاند، را نشان میدهد. این سیستم کشف افراد بیهدف به یک محصول واقعی تبدیل شده است که با نام NeoFace image data mining (IDM) برای مقاصد نظارتی در حوزه امنیت عمومی استفاده میشود.
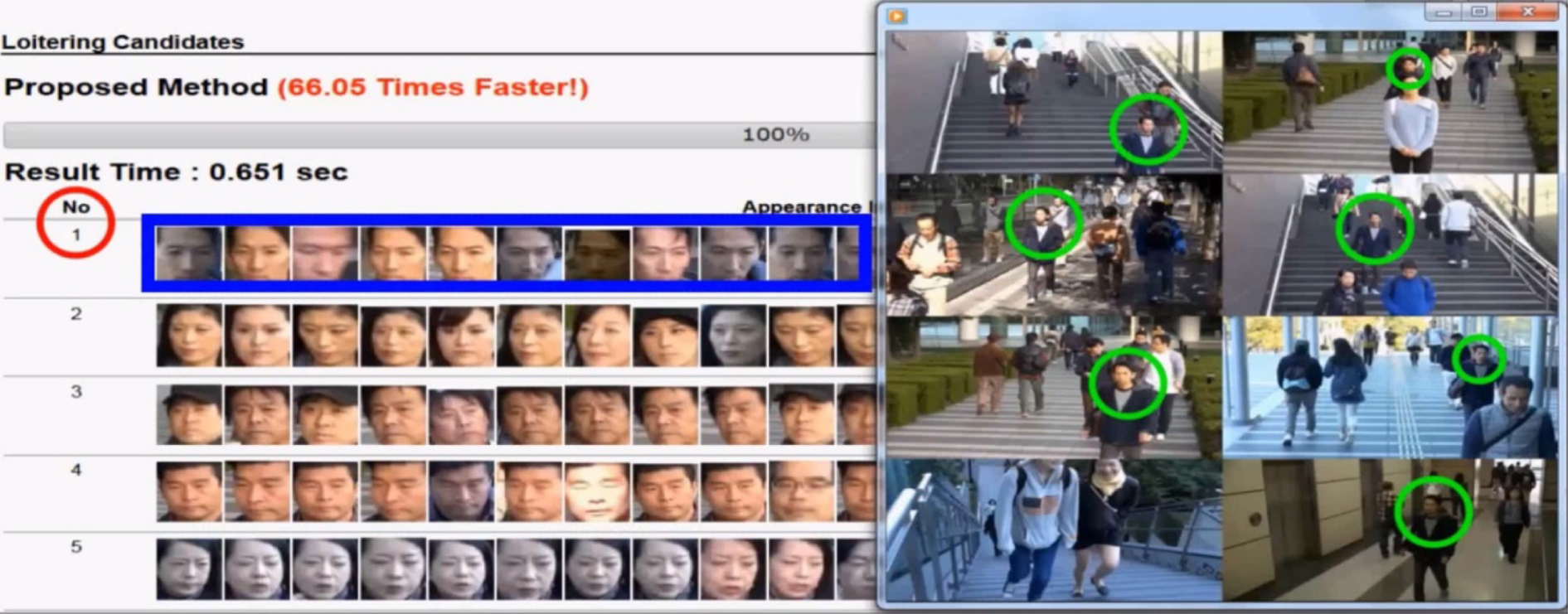
تصویر ۱۳. نتایج تجسمی [مرجع لیو، نیشیمورا و آراکی ۶۵] از نامزدهای بیحرکت کشف شده توسط AntiLoiter [مرجع لیو، نیشیمورا و آراکی ۶۳].
در دومین برنامه، با اینکه این سیستم خودکار میتواند نامزدهای بیهدف مکرر را کشف کند، هنوز از این دور بود که تصمیم واضحی را برای شناسایی افراد بیهدف واقعی بگیرد. به همین دلیل، ما سیستم AntiLoiter را گسترش دادیم تا ویژگیهای الگوهای ظاهری نامزدهای بیهدف را تجزیه و تحلیل کنیم. با استفاده از آنتروپی ریاضی، مدل تحلیلی نوینی را توسعه دادیم که تغییرات حرکت، مدت زمان و دوباره ظاهر شدن نامزدهای بیهدف را به دست میآورد و این امکان را فراهم میکند تا ویژگیهای رفتاری مربوط به افراد بیهدف واقعی را درک کنیم. همانطور که در شکل ۱۴ نشان داده شده است، افراد بیهدف ممکن است در الگوهای گرافیکی مشابهی از تغییر آنتروپی (hej) مانند منحنیهای آبی، قرمز و سبز ظاهر شوند. به این منظور، ما VisLoiter را گسترش دادیم [Reference Liu, Nishimura and Araki65] و آن را به یک سیستم به نام VisLoiter+ [Reference Sandifort, Liu, Nishimura and Hürst68] تبدیل کردیم که نتایج کشف افراد بیهدف را بهبود میبخشد و در شکل ۱۵ نشان داده شده است.
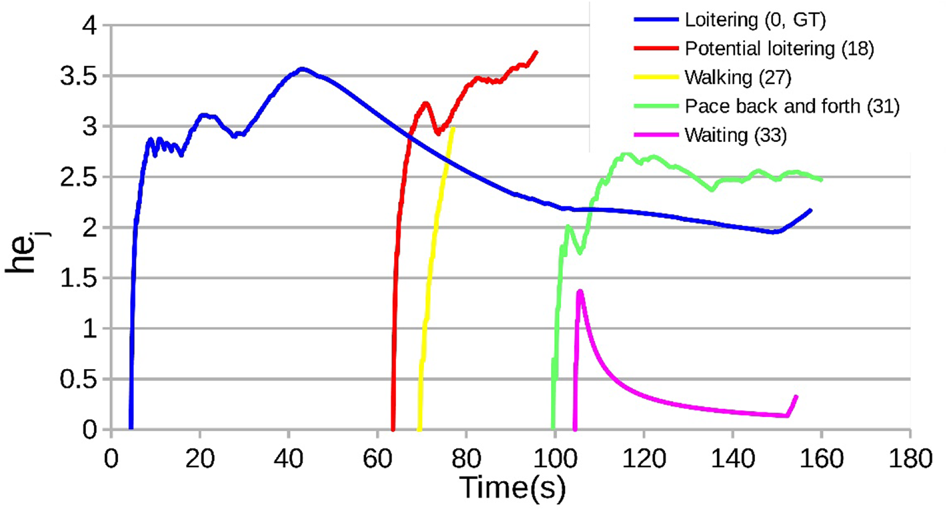
تصویر ۱۴. نمونه هایی از الگوهای رفتاری مربوط به بیحرکت های پتانسیلی.
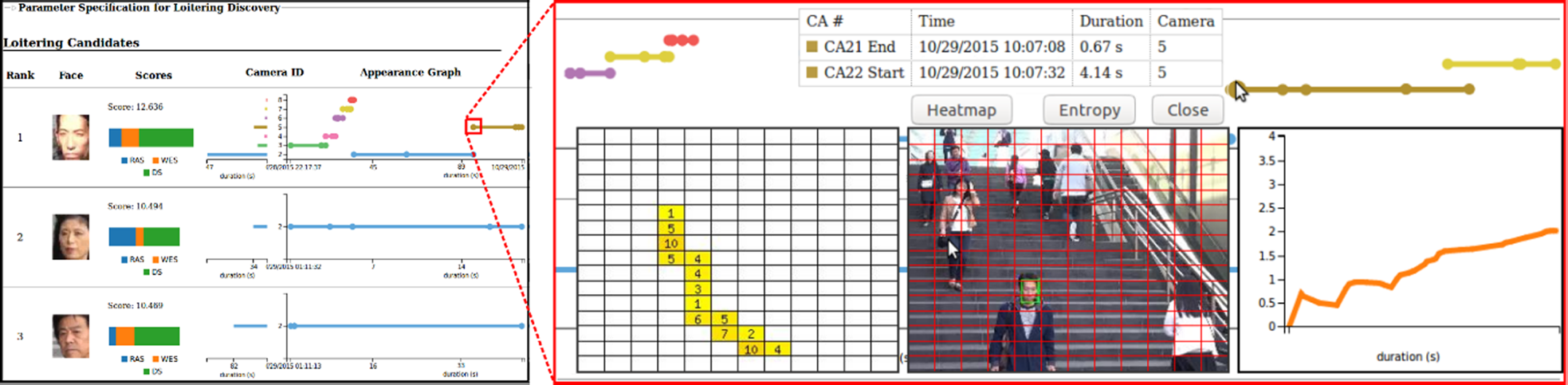
تصویر ۱۵. سیستم VisLoiter+ [مرجع سندیفورت، لیو، نیشیمورا و هورست ۶۸] با مدلهای پیشنهادی در [مرجع سندیفورت، لیو، نیشیمورا و هورست ۶۷] پیادهسازی شده است.
سوم، برای نشان دادن قابلیت بازیابی افراد با استفاده تنها از تشخیص چهره، یک روش نوین برای کشف "الگوهای دنبالکننده" [مرجع لیو، یونگ، نیشیمورا و آراکی ۶۹] بر اساس تطبیق مجدد شخص و کشف مکرر کنندههای مکث توسعه دادیم. شکل ۱۶ نمونهای از یک سناریوی دنبال کردن [مرجع لیو، یونگ، نیشیمورا و آراکی ۶۹] را نشان میدهد که در آن همان مرد (در یک جعبه سبز رنگ مشخص شده است) در دوربینهای نظارتی مختلف به همراه همان زن (در یک جعبه قرمز رنگ مشخص شده است) دنبال کردند. ایده کلیدی رویکرد ما بازیابی همان فرد در ویدئوها از دوربینهای مختلف است و سپس استخراج الگوهای مکرر همزمان شخص-زن از ویدئوها را به صورتی کارآمد انجام دهیم، مانند استفاده از لوئیجی برای فهرست کردن تعداد بزرگی از دادههای ویژگی.

تصویر ۱۶. نمونه ای از سناریوی تعقیب [مرجع لیو، یانگ، نیشیمورا و آراکی ۶۹].
علاوه بر سه مورد استفادهی گفتهشده در صحنههای واقعی با استفاده از تکنولوژی تشخیص چهره، بسیاری از کاربردهای جالب و پتانسیلی وجود دارد که مربوط به تطبیق مجدد گروه و تحلیل فعالیت گروه هستند. برای جوامع تحقیقاتی، بررسی پتانسیل اتخاذ تشخیص تنها با استفاده از تشخیص چهره در جهتی ساده اما چالش برانگیز برای کاربردهای واقعی، مثمرثمر خواهد بود.
جمعبندی و چالشهای آینده
در این مقاله، ما به بررسی تکنولوژی تشخیص چهره، تکنولوژی PAD برای استفاده عملی از تشخیص چهره، تخمین نگاه و تطبیق مجدد شخص به عنوان یکی از فناوریهای کاربردی و IDM با تحلیل سری زمانی پرداختیم.
برای هدایت جهت آینده، چالشهای تحقیقاتی که هنوز نیاز به پاسخگویی دارند برای کاربردهای عملی بیشتر به شرح زیر پیشنهاد میشود.
1. الگوریتمهای تشخیص چهره مناسب برای تغییرات ظاهری چهره در طول عمر از نوزادی تا پیری. عدم تغییرپذیری در طول عمر، عامل بسیار مهمی برای تشخیص چهره است. به ویژه، سوال اینکه تصاویر چهره ثبت شده برای نوزادان یا کودکان چه مدت کار خواهد کرد، از دیدگاه چالشهای فنی و محدودیتها جالب است.
2. مقابله با پوششهای مقابله با تشخیص چهره. اگرچه دقت بالای مطابقت در شرایط عادی قبلاً پیشبینی شده است، اما بهبود در شرایطی که افرادی که باید تأیید شوند، از ماسک چهره و / یا عینک آفتابی استفاده میکنند یا چهرهشان توسط شال یا ریش کاملاً پوشیده شده است، لازم است.
3. بهبود دقت تطبیق برای تأیید شخصیت دوقلوها، خواهران و برادران یا خویشاوندان. این هنوز چالش فنی است [مرجع گروتر، گروتر، نگان و هانائوکا ۱۹]. شباهت چهره دوقلوهای غیر همسر، بیشتر از همان شخص در سنین مختلف است.
ما همچنین پیشنهاد میدهیم تا فناوری عملی و مقاومتری برای تشخیص تقلب چهره و محافظت در برابر انواع حملات، فنونی برای حفاظت از مقادیر ویژگی قالب ارائه داده شده و فناوری محافظت برای مقابله با حملات سایبری توسط هوش مصنوعی را توسعه داده و با تکنولوژی تشخیص چهره موجود ترکیب کنیم. با توسعه چنین فناوریهایی، تشخیص چهره در جامعه به طور گستردهتری پیشرفت خواهد کرد.
هیتوشی ایماوکا در سال ۱۹۹۷ مدرک دکترای مهندسی در فیزیک کاربردی را از دانشگاه اوساکا دریافت کرد. او از سال ۱۹۹۷ در شرکت NEC Corporation کار میکند و در حال حاضر به عنوان یکی از اعضای ارشد NEC در حوزه مسائل فنی فعالیت میکند. علاقههای تحقیقی او شامل توسعه، تحقیق و صنعتیسازی تشخیص چهره، بیومتریک و پردازش تصویر پزشکی است.
هیروشی هاشیموتو در سال ۲۰۱۱ مدرک کارشناسی ارشد خود را از دانشگاه شهری توکیو دریافت کرد و در سال ۲۰۱۶ مدرک دکترای فیزیک خود را از دانشگاه توهوکو دریافت کرد. او در حال حاضر به عنوان یک پژوهشگر در آزمایشگاه تحقیقات بیومتریک شرکت NEC کار میکند. علاقههای تحقیقی او شامل یادگیری عمیق، بینایی ماشین، و احراز هویت بیومتریک است.
کوئیچی تاکاهاشی در سال ۲۰۱۲ مدرک کارشناسی ارشد خود را از دانشگاه کشاورزی و فناوری توکیو دریافت کرد و در سال ۲۰۱۵ مدرک دکترای خود را از دانشگاه کئیو دریافت کرد. او در حال حاضر به عنوان یک پژوهشگر در آزمایشگاه تحقیقات بیومتریک شرکت NEC کار میکند. علاقههای تحقیقی او شامل تشخیص چهره و کاربردهای آن است.
اکینوری اف. ابیهارا در سال ۲۰۰۸ مدرک کارشناسی ارشد خود را در زمینه فیزیک بیوفیزیک و بیوشیمی از دانشگاه توکیو دریافت کرد و در سال ۲۰۱۵ مدرک دکترای خود را در زمینه علوم زیستی از دانشگاه راکفلر دریافت کرد. در حال حاضر، او به عنوان مدیر کمکی در آزمایشگاه تحقیقات بیومتریک شرکت NEC فعالیت میکند. علاقههای تحقیقی او شامل یادگیری ماشین الهامگرفته از طبیعت، آزمون نسبت احتمالات متوالی، تشخیص چهره و تشخیص حملات ارائه است.
جیانکوان لیو در سال ۲۰۰۹ مدرک کارشناسی ارشد و دکترای خود را از دانشگاه تسوکوبا در ژاپن دریافت کرد. او در سالهای ۲۰۰۵ تا ۲۰۰۶ به عنوان یک مهندس توسعه در Tencent Inc. کار کرده است و در سال ۲۰۱۰ به عنوان دستیار پژوهشی در دانشگاه چینی هونگ کونگ به عنوان یک پژوهشگر در شرکت NEC پیوست. او در حال حاضر به عنوان یک پژوهشگر اصلی در آزمایشگاه تحقیقات بیومتریک شرکت NEC فعالیت میکند و به عنوان دستیار استاد در دانشگاه Hosei در ژاپن فعالیت میکند. علاقههای تحقیقی او شامل پایگاههای داده چندرسانهای، استخراج داده، بازیابی اطلاعات، محاسبات ابری و تحلیل شبکههای اجتماعی است. در حال حاضر، او به عنوان ویراستار همکار IEEE MultiMedia و Journal of Information Processing، هممدیر کلی IEEE MIPR 2021 و هممدیر کنفرانسهای سری IEEE از جمله ICME 2020، BigMM 2019، ISM 2018، ICSC 2017 و غیره خدمت میکند/کرده است. او عضو IEEE، ACM، IPSJ، APSIPA و جامعه پایگاه داده ژاپن (DBSJ) است.
آکیهیرو هایاساکا در سال ۲۰۰۴ مدرک کارشناسی ارشد خود را از دانشگاه توهوکو دریافت کرد و در سال ۲۰۰۹ مدرک دکترای خود را در علوم اطلاعات دریافت کرد. او در حال حاضر به عنوان یک پژوهشگر در آزمایشگاه تحقیقات بیومتریک شرکت NEC فعالیت میکند. علاقههای تحقیقی او شامل تشخیص چهره و فناوریهای حومه آن است.
یوسکه موریشیتا در سال ۲۰۰۸ مدرک کارشناسی ارشد خود را از دانشگاه تسوکوبا دریافت کرد. در حال حاضر، او به عنوان یک پژوهشگر اصلی در آزمایشگاه تحقیقات بیومتریک شرکت NEC فعالیت میکند. علاقههای تحقیقی او شامل تشخیص چهره، تشخیص پیادهرو و تخمین نگاه است.
کازویوکی ساکورای در سال ۱۹۹۵ مدرک کارشناسی ارشد خود را از دانشگاه توکیو دریافت کرد. در حال حاضر، او به عنوان یک مهندس ارشد در آزمایشگاه تحقیقات بیومتریک شرکت NEC فعالیت میکند. علاقههای تحقیقی او شامل تشخیص تصویر، تشخیص چهره، شناسایی مجدد فرد و تشخیص حملات ارائه است.
منبع:


