











چکیده:
شناسایی چهره در چند سال اخیر به عنوان یک حوزه پژوهشی جالب مورد توجه قرار گرفته است زیرا در چندین برنامه از جمله مدیریت حضور و غیاب و سیستم های کنترل دسترسی نقش اساسی در احراز هویت بیومتریکی انسان ایفا می کند. سیستم های مدیریت حضور و غیاب برای تمام سازمان ها بسیار مهم هستند، اما مدیریت ورودی و خروجی منظم حضور و غیاب پیچیده و زمان بر است. روش های شناسایی انسان خودکار زیادی از جمله بیومتریک، RFID، ردیابی چشم و تشخیص صدا وجود دارند. چهره یکی از گسترده ترین بیومتریک ها برای احراز هویت انسان است. در این مقاله، یک سیستم حضور و غیاب تشخیص چهره بر اساس شبکه های عصبی کانولوشنی عمیق یادگیری انتقالی ارائه شده است. با استفاده از سه شبکه عصبی کانولوشنی پیش آموزیده و آنها را بر روی داده خود آموزش دادیم. سه شبکه عملکرد بسیار خوبی در ارتباط با دقت پیش بینی بالا و زمان آموزش مناسب نشان دادند.
مقدمه:
همه سازمان ها به یک سیستم مدیریت حضور و غیاب برای نگهداری سوابق حضور و غیاب کارکنان خود، به صورت دستی یا خودکار، نیاز دارند. حضور و غیاب روزانه دانشجویان در کلاس برای ارزیابی عملکرد و کیفیت ضروری است.
مانیتورینگ. صدا زدن نام ها یا امضا کردن روی کاغذها، روش های سنتی استفاده شده در بیشتر سازمان ها هستند که هر دو مصرف زمانی زیادی دارند و ناامن هستند [1]. از طرف دیگر، بیشتر سیستم های شناسایی خودکار انسان بر پایه روش های سنتی مانند اثر انگشت، رمز عبور و اسکن کارت شناسایی کاربرد دارند. با این حال، همه این روش ها محدودیت هایی مانند فراموش کردن رمز عبور یا گم شدن کارت شناسایی دارند. بنابراین، مطمئن ترین روش برای اطمینان از امنیت کامل و ذخیره سوابق تاریخی از طریق سیستم هوشمند تشخیص چهره است [2]. این حوزه در زمان اخیر به سرعت در حال رشد است و نقش مهمی در امنیت ایفا می کند، زیرا تکنیک بسیار دقیقی برای شناسایی و تأیید هویت افراد است [3] [4].
یادگیری انتقالی یک شکل از یادگیری ماشین است که در آن یک مدل برای یک وظیفه خاص ساخته شده و به عنوان نقطه شروع برای تغییرات در وظیفه دوم استفاده می شود. در یادگیری عمیق به عنوان یک مدل پیش آموزش دیده در وظایف بینایی ماشین و پردازش زبان طبیعی برای توسعه مدل های شبکه عصبی بر روی این مسائل استفاده می شود [5]. یادگیری انتقالی در مسائل یادگیری عمیق بسیار مفید است زیرا بیشتر مسائل واقعی دارای میلیاردها داده برچسب خورده هستند و این نیاز به مدل های پیچیده را دارد [6]. این یک تکنیک کاملاً مناسب برای بهینه سازی، صرفه جویی در زمان و دستیابی به عملکرد بهتر است. توسعه دهندگان می توانند از یادگیری انتقالی برای ادغام برنامه های مختلف در یکی استفاده کنند. آنها می توانند به سرعت مدل های جدیدی را برای برنامه های پیچیده آموزش دهند. علاوه بر این، یادگیری انتقالی ابزار خوبی برای بهبود دقت مدل های بینایی ماشین است [5].
در این کار، یک سیستم حضور و غیاب تشخیص چهره بر اساس شبکه های عصبی کانولوشنی عمیق (CNN) ارائه شده است. ما با استفاده از سه شبکه عصبی کانولوشنی پیش آموزیده و آنها را بر روی داده های خود که شامل 10 کلاس مختلف است و هر کلاس شامل 20 تصویر چهره است، آموزش دادیم. سه شبکه با دقت پیش بینی بالا و زمان آموزش مناسب، عملکرد بسیار خوبی را نشان دادند.
-
شبکه های پیش آموزش دیده
شبکه های CNN پیش آموزش دیده ویژگی های متمایزی دارند که در انتخاب یک شبکه برای مقابله با مسئله خاصی مهم است. دقت، سرعت و اندازه شبکه مهمترین ویژگی ها هستند. به طور کلی، انتخاب یک شبکه بین این وظایف تنظیم می شود. برای افرادی که می خواهند یک الگوریتم یاد بگیرند یا یک سیستم برپایی شده را تست کنند، مدل های پیش آموزش دیده منبع عالی پشتیبانی هستند [7]. همیشه ممکن نیست یک مدل را از ابتدا بسازید به دلیل محدودیت های زمانی یا محاسباتی، به همین دلیل مدل های پیش آموزش دیده وجود دارند. چندین مدل CNN پیش آموزش دیده به صورت عمومی در دسترس هستند [8]. در این کار، ما سه شبکه پیش آموزش دیده را بررسی کردیم؛ AlexNet، GoogleNet و SqueezeNet.
2.1. AlexNet
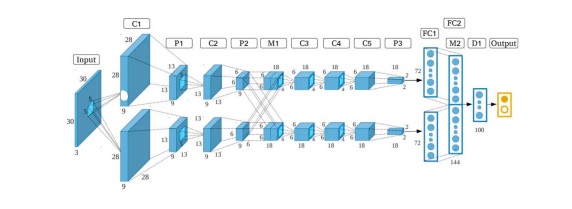
یکی از رایج ترین معماری های شبکه های عصبی تا به حال، AlexNet است. این برای آموزش میلیون ها تصویر و دسته بندی آنها به دسته های شیء مانند چهره ها، میوه ها، لیوان ها، مداد ها و حیوانات استفاده شده است. به عنوان ورودی، شبکه یک تصویر را دریافت کرده و برچسب آن شیء در تصویر را خروجی می دهد. همچنین، احتمالات برای هریک از دسته های شیء. ابعاد ورودی شبکه 227 × 227 × 3 تصویر RGB هستند [9] [10] [11] [12]. معماری AlexNet در شکل 1 نشان داده شده است.
2.2. GoogleNet
ساختار GoogleNet شامل 22 لایه عمیق و همچنین 5 لایه پولینگ است [13]. در کل، 9 ماژول شروع خطی را قابلیت ادغام به حافظه کامپیوتر به راحتی بیشتری دارند و می توانند به راحتی از طریق شبکه های کامپیوتری ارتباط برقرار کنند [9] [14] [12]. معماری شبکه SqueezeNet در شکل 3 نشان داده شده است.
-
شکل 1. معماری AlexNet [12].
-
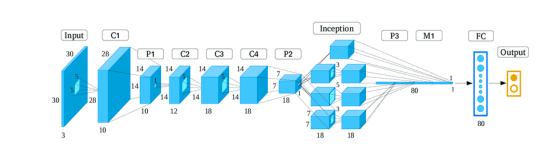 شکل 2. معماری GoogleNet [12].
شکل 2. معماری GoogleNet [12]. -
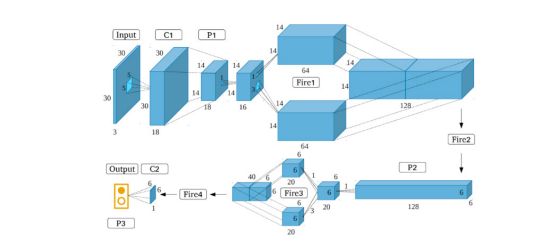 شکل 3. معماری SqueezeNet [12].
شکل 3. معماری SqueezeNet [12].-
کارهای مرتبط
شناسایی چهره توسط چندین پژوهشگر بررسی شده است. یک راه حل موجود [15] از یک تکنیک شناسایی چهره استفاده کرد که از ویژگی های مشتق شده از ضرایب تبدیل کسینوسی گسسته (DCT) استفاده می کند، به همراه یک
برای شناسایی چهره، یک ردهبند مبتنی بر نقشه خودسازمانده (SOM) استفاده شده است. در نرمافزار MATLAB، این روش با استفاده از تصاویر چهره با انواع عبارات صورتی آزمایش شده است. با آمادهسازی برنامه برای حدود 850 دور بازپردازی، دستگاه میتواند با دقت 81.36% در 10 آزمایش متوالی شناسایی را انجام دهد. با اختصاص حجم کمی از ویژگیها، این روش به خوبی برای پیادهسازی سختافزاری برای کارهای دنبالهای و با هزینه کم مناسب است.
Arsenovic و همکاران [16] یک سیستم حضور و غیاب شناسایی چهره مبتنی بر یادگیری عمیق پیشنهاد کردهاند. این مدل از چندین مرحله کلیدی تشکیل شده است که با استفاده از جدیدترین تکنیکهای موجود امروزی مانند کسری از شبکههای عصبی برای تشخیص چهره و شبکههای عصبی برای تولید Embedding چهره توسعه یافتهاند. در یک مجموعه داده محدود از تصاویر اصلی چهره کارکنان در جهان واقعی، دقت کلی 95.02٪ بوده است. این مدل شناسایی چهره پیشنهادی میتواند در سایر سیستمها نیز استفاده شود.
Fu و همکاران [17] یک راه حل پیشنهاد کردهاند که دو الگوریتم یادگیری عمیق، شبکه عصبی کانولوشنی چندوظیفهای (MTCNN) برای تشخیص چهره و شناسایی مرکز چهره را ترکیب میکند تا یک سیستم حضور و غیاب خودکار در کلاس دانشگاه ایجاد کند. سیستم، حضور و غیاب خودکار را برای سه نوع تخلف از نظم کلاس گزارش میدهد: غیبت، تأخیر و خروج زودهنگام، بر اساس تعداد قابل توجهی یافتههای آزمایشی. پس از کلاس، جدول حضور و غیاب با وضعیت یادگیری تمام دانشجویان به صورت خودکار ثبت میشود. این سیستم با دقت بالا، چهرهها را به طور سریع شناسایی میکند و با دقت 98.87٪، نرخ تشخیص صحیح کمتر از 1/1000 و نرخ تشخیص اشتباه 93.7٪ دارد.
Zulfiqar و همکاران [18] یک سیستم شناسایی چهره مبتنی بر شبکههای عصبی کانولوشنی پیشنهاد کردهاند که با استفاده از دستگاه تشخیص چهره Viola-Jones [19]، چهرهها را در تصویر ورودی شناسایی کرده و ویژگیهای چهره را به صورت خودکار از چهرههای شناسایی شده با استفاده از یک شبکه عصبی پیشآموزش دیده برای شناسایی استخراج میکند. برای آموزش کارآمد شبکه عصبی کانولوشنی، یک پایگاه داده بزرگ از تصاویر چهره افراد ایجاد شده است که برای افزایش تعداد تصاویر برای هر فرد و ارائه شرایط روشنایی و نویز متنوع تقویت شده است. علاوه بر این، برای شناسایی چهره عمیق، یک مدل شبکه عصبی پیشآموزش دیده بهینه و مجموعهای از پارامترهای هایپرآموزش انتخاب شده است. اثبات کارآیی شناسایی چهره عمیق در سیستمهای احراز هویت بیومتریک خودکار با دقت کلی 98.76٪ در نتایج آزمایشی روشنکننده است.
-
روش
روش پیشنهادی شامل چندین مرحله است: جمعآوری داده، پیشپردازش داده، افزایش داده، آموزش و اعتبارسنجی شبکه عصبی کانولوشنی و آزمایش سیستم است.
4.1. جمعآوری داده
پایگاه داده ما شامل 200 تصویر است که با استفاده از دوربین جلویی iPhone 12 با لنز 12 مگاپیکسلی f/2.2 جمعآوری شده است. دادهها به 10 کلاس تقسیم شدهاند و هر کلاس شامل 20 تصویر است. این 10 کلاس، 10 نفر از هر دو جنس را نشان میدهند که در شکل 4 نمایش داده شده است.
-

-
شکل 4. پایگاه داده
4.2. فرمت دادهها
-
دادههای جمعآوری شده با فرمت فایل JPG استفاده میشوند. اندازه تصاویر بین 3.00 مگابایت و 4.00 مگابایت است. هر شبکه از ورودی با اندازه متفاوتی استفاده میکند. بنابراین، باید تصاویر را به اندازه ورودی مورد نظر هر شبکه تغییر اندازه دهیم. شبکههای SqueezeNet و AlexNet از اندازه 227 × 227 استفاده میکنند، در حالی که GoogleNet از اندازه 224 × 224 استفاده میکند. تمام تصاویر گرفته شده در رنگهای RGB هستند که برای استخراج ویژگیهای صحیح مناسب هستند.
4.3. افزودن داده
افزایش حجم داده با وارد کردن نسخههای کمی تغییر یافته از دادههای موجود یا تولید دادههای تصنعی از دادههای موجود از ابزار افزایش داده استفاده میشود. این ابزار به منظور تنظیم و کمینهسازی افراطگرایی در آموزش مدل یادگیری ماشین استفاده میشود. در یادگیری عمیق، افزودن داده به صورت تغییرات هندسی، برعکس کردن تصویر، تغییر رنگ، برش، چرخش، داشتن نویز و حذف تصادفی استفاده میشود تا تصویر را بهبود بخشد [8]. در شبکههای آموزش دیدهشده ما، با گرفتن چند تصویر از زوایای مختلف، محیطها و شرایط، جهت، موقعیت و روشنایی، از افزودن داده استفاده کردیم که در شکل 5 نشان داده شده است. پس از وارد کردن داده به شبکه، دو نوع افزودن داده اعمال شد که شامل چرخش و مقیاسبندی است. برای هر تصویر، یک چرخش تصادفی با زاویه بین -90 تا 90 درجه انجام میشود. برای هر تصویر، یک مقیاسبندی تصادفی با عاملی بین 1 تا 2 انجام میشود.

شکل 5. نمونههایی از افزودن داده.
4.4. انتخاب شبکههای پیشآموزش داده شده
برای آموزش شبکه عصبی کانولوشنی بر دادههای ما، 3 شبکه را انتخاب کردیم که شامل شبکههای SqueezeNet، AlexNet و GoogleNet میشوند. SqueezeNet یک CNN کوچک است و نیاز به کمترین ارتباط بین سرورها در طول آموزش توزیع شده دارد. CNNهای کوچک همچنین راحتتر بر روی سختافزار با حافظه محدود، مانند FPGA، پیادهسازی میشوند.
AlexNet میتواند به راحتی ویژگیهای یادگرفته شده را با تعداد کمتری تصاویر آموزشی به یک تخصیص ویژه منتقل کند. AlexNet برای بهبود عملکرد چالش ImageNet توسعه داده شد. این اولین شبکه کانولوشنی عمیق بود که به دقت قابل توجهی رسید. مسئله افراطگرایی نیز توسط AlexNet با استفاده از لایههای drop-out حل شد که در آن هنگام آزمایش یک اتصال با احتمال p = 0.5 حذف میشود. احتمال 0.5 انتخاب شده است زیرا بهترین احتمال برای تطبیق با مشخصات و تنظیمات شبکه بوده است. این تنظیمات پس از بسیاری از آزمایشها و تغییرات تعیین شد. این باعث میشود که شبکه ترکیب بدیهی از حداقلهای محلی بد را پیشگیری کرده ولی تعداد بارهای لازم برای همگرایی به دو برابر افزایش مییابد.
ماژول شروع در معماری GoogleNet بیشترین چالشهای شبکههای بزرگ را حل کرد. GoogleNet با نرخ خطای 6.67٪ که نزدیک به عملکرد سطح انسان است، ساختاری با 22 لایه از CNN عمیق دارد که تعداد پارامترها را به 4 میلیون کاهش میدهد (60 میلیون در مقابل AlexNet).
4.5. تنظیم شبکه پیشآموزش داده شده
در هر یک از سه شبکه استفاده شده، پارامترهای شبکه پیشآموزش داده شده که شامل لایه کانولوشن 2D و لایه خروجی طبقهبندی هستند، تنظیم شد. در طراح عمیق شبکه، اندازه فیلتر را به 1 × 1 و تعداد فیلترها را به 10 تغییر دادیم که همان 10 کلاس داده ما هستند، همانطور که در شکل 6 نشان داده شده است. لایه خروجی طبقهبندی را نیز برای سازگاری با طبقهبندی و برچسبهای خروجی خود تغییر دادیم.
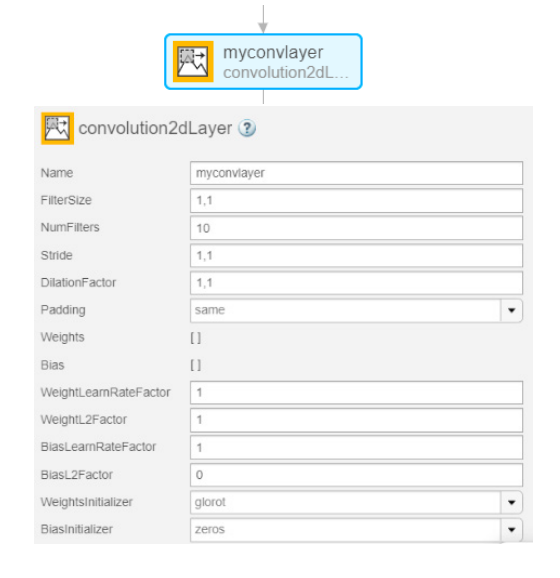
شکل 6. تنظیم لایه کانولوشن.
4.6. آموزش
روند عمومی در آموزش هر شبکه با استفاده از یادگیری انتقالی با تغییر پارامترهای مربوط به معماری پایه شروع میشود. این شامل انتخاب نرخ یادگیری مناسب، زمان آموزش، تعداد دورهها و فرکانس اعتبارسنجی است. هنگامی که نرخ اولیه کم است، فرایند آموزش ممکن است بهطور کلی متوقف شود و هنگامی که نرخ بسیار بالا است، فرآیند آموزش ممکن است ناپایدار یا یک مجموعه وزنهای نامناسب را به سرعت یاد بگیرد. بنابراین، ما نرخ یادگیری اولیه را برابر با 0.0001، فرکانس اعتبارسنجی را برابر با 10 و حداکثر دورهها را برابر با 30 انتخاب کردیم، زیرا باید به اندازه امکان بالا باشد تا خطاهای آموزش متوقف شدن را حذف کند. به طور خاص، یک دوره یک چرخه یادگیری است که در طول آن، یادگیرنده به کل مجموعه دادههای آموزشی معرفی میشود. همچنین، حداقل اندازه دسته برابر با 11 است که با نیازهای حافظه (8.00 گیگابایت) سختافزار CPU که با سرعت 1.8 گیگاهرتز کار میکند، سازگار است. با افزایش تعداد دورهها، دقت شبکه بالاتر میرود. بنابراین، ما باید یک شماره بزرگتر را انتخاب کنیم. مجموعه داده به صورت تصادفی به دو بخش تقسیم شد: 70٪ داده برای آموزش استفاده میشود و 30٪ داده برای اعتبارسنجی استفاده میشود. پارامترهای آموزش در شکل 7 نشان داده شده است.
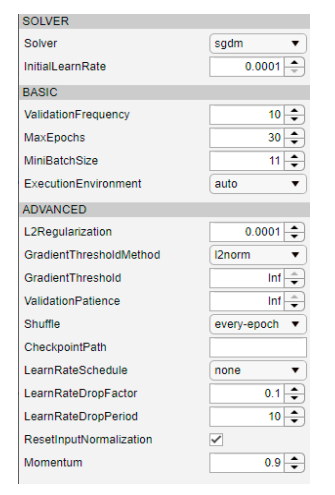
شکل 7. گزینههای آموزش.
-
نتایج و بحث
آموزش SqueezeNet نیاز به 30 دوره با 12 بار در هر دوره داشت تا شبکه به خوبی دادهها را آموزش دهد و آنها را اعتبارسنجی کند. پس از 360 بار، به دقت اعتبارسنجی 98.33٪ رسید. فرایند آموزش 26 دقیقه و 53 ثانیه طول
- کشید. علاوه بر این، فرکانس اعتبارسنجی در یک فرایند 10 باری انجام شد تا اطمینان حاصل شود که سیستم به خوبی آموزش دیده است اما داده را بیش از حد آموزش نداده است.
آموزش GoogleNet نیز نیاز به 30 دوره با 12 بار در هر دوره داشت تا شبکه به خوبی دادهها را آموزش دهد و آنها را اعتبارسنجی کند. پس از 360 بار، به دقت اعتبارسنجی 93.33٪ رسید. شبکه 39 دقیقه و 21 ثانیه برای تکمیل آموزش طول کشید. علاوه بر این، اعتبارسنجی در یک فرایند 10 باری انجام شد تا اطمینان حاصل شود که سیستم به خوبی آموزش دیده است اما داده را بیش از حد آموزش نداده است.
آموزش AlexNet نیاز به 60 دوره با 12 بار در هر دوره داشت تا شبکه به خوبی دادهها را آموزش دهد و آنها را اعتبارسنجی کند. پس از 720 بار، به دقت اعتبارسنجی 100٪ رسید که دقت بسیار بالایی است و نشانگر یک شبکه به خوبی آموزش دیده است. زمان آموزش شبکه 76 دقیقه بود که نسبت به دو شبکه قبلی طولانی است. علاوه بر این، اعتبارسنجی در یک فرایند 10 باری انجام شد تا اطمینان حاصل شود که سیستم به خوبی آموزش دیده است اما داده را بیش از حد آموزش نداده است.
ما از یک سیستم تشکیل شده از یک CPU تکی استفاده کردیم که با سرعت 1.8 گیگاهرتز و 8.00 گیگابایت RAM کار می کند. همانطور که در شکل 8 نشان داده شده است، ما از همان نرخ یادگیری اولیه، بیشترین تعداد بار و یک CPU تکی برای سه شبکه استفاده کردیم، در حالی که تعداد دورهها برای هر شبکه متفاوت بود. به طور کلی، مشاهده میشود که AlexNet بهترین شبکه با دقت اعتبارسنجی است اما زمان آموزش آن بیشتر است به دلیل تعداد پارامترها. SqueezeNet دومین گزینه است که با زمان آموزش حداقلی که 26 دقیقه و 53 ثانیه است، دقت 98.33٪ را ارائه می دهد. GoogleNet دقت پایینتری را نسبت به سایر شبکهها دارد. نتایج آموزش و اعتبارسنجی سه شبکه در جدول ۱ خلاصه شده است.
الحنائي و همکاران / مجله علوم کامپیوتر Procedia 00 (2021) 000-000
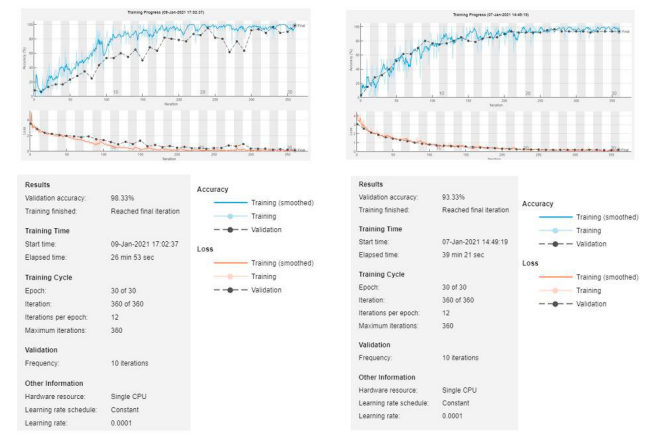
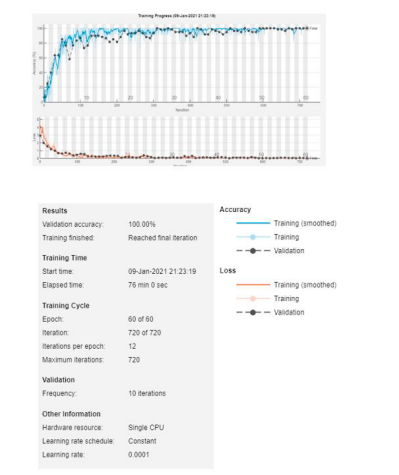
شکل 8. نتایج آموزش و اعتبارسنجی شبکه های عصبی پیچشی (CNN) (a) SqueezeNet؛ (b) GoogleNet؛ (c) AlexNet.
جدول 1. نتایج آموزش شبکه های عصبی پیچشی (CNN).
مدل نرخ یادگیری دوره ها دقت اعتبارسنجی زمان گذرانده سخت افزار بیشینه تکرارها
SqueezeNet 0.0001 30 98.33٪ 26 دقیقه و 53 ثانیه CPU تکی 360
GoogleNet 0.0001 30 93.33٪ 39 دقیقه و 21 ثانیه CPU تکی 360
AlexNet 0.0001 60 100٪ 76 دقیقه و 0 ثانیه CPU تکی 720
زمانی که برای تصاویر نامعلوم از ده کلاس مختلف تست شد، سه مدل CNN قادر به با موفقیت تشخیص چهرهها با اطمینان پیشبینی بسیار بالا بودند. درصدی که در بالای تصاویر نشان داده شده است، به سطح اطمینان شبکه آموزش دیده برای پیشبینی برچسبهای مربوطه اشاره دارد. سطح اطمینان بسیار بالا نشان میدهد که مدل با موفقیت تصویر را پیشبینی کرده است. شکل 9a، 9b و 9c مثالهایی از نتایج به دست آمده توسط SqueezeNet، GoogleNet و AlexNet را نشان میدهند.
برای تحلیل نتایج، ما از همان نرخ یادگیری اولیه، بیشترین تعداد تکرارها و یک CPU تکی برای شبکه ها استفاده کردیم، در حالی که تعداد دوره ها برای هر شبکه متفاوت بود. مشاهده میشود که AlexNet بهترین شبکه برای آموزش دادهها است زیرا دقت اعتبارسنجی بالاترین است اگرچه زمان آموزش طولانی تری دارد. SqueezeNet دومین گزینه است که با حداقل زمان گذرانده شده 26 دقیقه و 53 ثانیه، دقت 98.33٪ را ارائه میدهد. GoogleNet سومین شبکه برتر است زیرا دقت پایینتری را نسبت به سایر شبکه ها دارد.
شکل 9. نتایج آزمون (a) SqueezeNet؛ (b) GoogleNet؛ (c) AlexNet.
در جدول 2، مقایسهای از روش پیشنهادی با روشهای قبلی نشان داده شده است. نتایج جدول 2 بر اساس مجموعه دادههای ما به دست آمده است. به وضوح نشان داده شده است که رویکرد پیشنهادی ما نسبت به روشهای دیگر عملکرد بهتری داشته است.
جدول 2. مقایسه روشهای تشخیص چهره.
نتیجه گیری
این مقاله یک سیستم حضور و غیاب تشخیص چهره بر پایه یادگیری عمیق ارائه میدهد. ما با استفاده از یادگیری انتقالی با سه شبکه عصبی پیچشی پیشآموزش داده شده، آنها را بر روی دادههای خود آموزش دادیم. در مقایسه با روشهای دیگر، سیستم نشان داد که در عملکرد با دقت پیشبینی بالا و زمان آموزش مناسب، عملکرد بسیار خوبی دارد. سه شبکه SqueezeNet، GoogleNet و AlexNet به ترتیب دقت اعتبارسنجی 98.33٪، 93.33٪ و 100٪ را داشتند. رویکرد پیشنهادی میتواند در سیستمهای حضور و غیاب و دسترسی به درها در سازمانهای مختلف مانند دولت و بخش خصوصی، فرودگاهها، مدارس و دانشگاهها استفاده شود. این کار با بررسی بیشتر مدلهای CNN پیشآموزش .داده شده و شامل بیشتر دادههای تصویری چهره انسان میتواند توسعه یابد. بررسی کاربرد این مدلها در وظایف شناسایی انسان با صورت ماسک زدنده نیز جالب است.
منبع : ساینس دایرکت